Mais uma dúvida sobre Entites X Repositories dentro de DDD
182 respostas
luizaso
Pessoal, li muitas da discussões aqui no fórum sobre Entities X Repositories, algumas muito acaloradas rsrsrsrsrs… mas ainda persistiu uma dúvida. Na verdade eu sou desenvolvedor do mundo .NET mas sempre visito os fóruns aqui do GUJ, pois neles encontro muita informação interessante que ainda hoje não é muito divulgada entre desenvolvedores em plataforma MS.
Estou apenas iniciando na utilização de DDD e tenho uma dúvida simples mas que ainda não me foi esclarecida mesmo após horas de leitura nos posts sobre o assunto aqui no GUJ.
No .NET quando vamos fazer a separação de Layers utilizamos projetos de classes diferentes e uma limitação que existe nesse caso é que não pode haver referência circular entre dois projetos.
Com essa limitação em mente e entendendo que a arquitetura que tenho proposto para um projeto pessoal no qual estou trabalhando atualmente se constitui de um modelo básico parecido com:
[Aplicação]-> [DDD: Entities, Repositories, etc] -> [Infraestrtura: DAL -> NHibernate]
surge a seguinte dúvida:
Eu tenho uma Entity User, esta Entity pode fazer referência direta ao meu DAO para as operações básicas de CRUD, ou seria parte de DDD que as minhas Entities utilizem o Repository para estas operações?
Sei que é uma dúvida primária, mas primário é o estado em que estou na utilização de DDD.
Olá Luiz.
Domain-Driven trabalha com o domínio do software e isso não contempla classes "DAO"s, que é apenas um pattern de abstração da persistência dos seus dados:
Repositories são dirigidos ao domínio e não a infraestrutura… ele esta (e faz parte) do domínio e se comunica com a camada de persistencia (normalmente DAOs Data Mappers):
Independente disso, uma entidade não deveria conter repositórios apenas para satisfazer métodos CRUDs.
Um Usuário que contenha operações como salvar e apagar (ele mesmo), descaracteriza seu objeto como uma Entity de um Domain Model e o torna parte de outro padrão, o Active Record.
Em Domain-Driven, é o repositório que deve adicionar ou remover entidades e não ela própria (não rola Active Record), portanto retire estes métodos de sua entidade.
Repositórios são úteis dentro da entidade, mas em outros casos. As vezes é necessário que um método de negócio (e não um simples CRUD) de uma Entity armazene informações ou realize consultas em uma única lógica
Normalmente um Service utiliza mais informações do repositório do que uma Entity, mas isso varia de caso a caso.
pcalcado
Oi, Luiz,
Sua dúvida não é básica e nem é tão relacionada com Doain-Driven Design. Procure ler sobre Dependency Inversion Principle. Eu escrevi um artigo que fala sobre isso para uma Mundo Java ou Mundo .Net (não lembro qual) mas dentro da plataforma da Microsoft existe um ótimo livro: Agile Principles, Patterns, and Practices in C# . Esse livro é uma versão C# do livro anterior do Uncle Bob, que usa Java: Agile Principles, Patterns, and Practices.
Basicamente o mesmo conteúdo em linguagens diferentes.
pcalcado
Não exatamente. Active Record está relacionado ao Data Mapper, uma Camada abaixo do Domínio. Um AR pode ser um Entity sem problemas e não é porque você não usa um padrão descrito em Domain-Driven Design que você não está usando Domain-Driven Design.
le-silva
Oi Luiz, um livro interessante sobre DDD com exemplos em C#…
Applying Domain-Driven Design and Patterns: With Examples in C# and .NET
Alessandro_Lazarotti
Uma entidade com responsabilidades de persistencia é uma salada de conceitos. Ela pode continuar sendo uma Entity, mas ao meu ver, mal modelada. Afinal de contas, o repository esta aí pra isso …
luizaso
Fala galera, obrigado pelas respostas até agora, está sendo muito esclarecedor.
Lezinho, apenas para esclarecer, se eu tenho uma entity que possui seus próprios métodos CRUD, se esta chama o Repositório para se auto-persistir, ainda assim seria incorreto de acordo com sua visão, ter esses métodos em minha Entity?
E se não for assim, ou seja decidi por não ter o CRUD em minhas Entities, no caso quando precisar persistir uma Entity, eu deveria faze-lo no meu Cliente (entenda-se por cliente, uma Fachada ou mesmo a minha aplicação) utilizando algo parecido com:
User user = new User();
// código que preenche as informações de user....
ProfileRepository.Save(user);
Mesmo assim ainda não estou convencido de qual o melhor e mais prático modelo a ser utilizado se entities com ou sem CRUD, mas gostaria de entender melhor sua visão.
Em meus estudos sobre DDD, não vi nenhum restrição em uma entity ter o CRUD em si, mas como a discussão sempre é esclarecedora, quero entender melhor cada um dos pontos aqui abordados.
Apenas para título de informação, se em meu projeto .NET eu decido manter em dois projetos diferentes os meus Repositories e meus Entities, crio um problema de referência, pois meu projeto Repositories precisa referênciar o projeto de Entities e o projeto de Entities, se precisar de um Repository, vai ter que referênciar Repositoreis, o que cria uma referência circular não aceita pelo .NET (como sitei em meu primeiro post), mesmo usando de Interfaces não consigo ver uma solução para isso, caso eu queira realmente manter as coisas em Assemblies separados.
gibaholms
Oi cara… na minha empresa trabalho também com .NET e temos este mesmo problema de referencia ciclica…
ai usamos um domain model que tem um certo overhead, pois criamos uma VO apenas para trafegar informação da camada de dominio pra camada de persistencia…
um cara aki estava propondo uma solução com reflection, ficava mto boa… evitava a referencia ciclica (pq vc referencia o objeto a partir do proprio assembly) e evitava o overhead de replicar as propriedades do dominio pra VO… a unica coisa ruim eh a complexidade mesmo, mas com umas factories acabou ficando bem legal
le-silva
Entities e Repositories fazem parte da mesma layer, a de domínio. Então, não há a necessidade de você colocá-las em projetos separados. Aliás, todo o teu aplicativo pode estar no mesmo projeto, tendo apenas uma divisão clara de layers.
Sobre a persistencias de suas entidades, é exatamente assim como você citou - Repository.add(entity). A único detalhe que acho que vale a pena citar, é que normalmente usamos termos pros métodos de repositório diferentes do que usamos em DAOs. Geralmente, em repositório:
add
remove
update ou merge
get
Porque esses termos abstraem um pouco mais a idéia de repositório, que não necessáriamente é um banco de dados relacional. Mas isso não é uma regra!
Abraço!
le-silva
Exemplo extraído do livro que te indiquei (capitulo 6):
Apenas para título de informação, se em meu projeto .NET eu decido manter em dois projetos diferentes os meus Repositories e meus Entities, crio um problema de referência, pois meu projeto Repositories precisa referênciar o projeto de Entities e o projeto de Entities, se precisar de um Repository, vai ter que referênciar Repositoreis, o que cria uma referência circular não aceita pelo .NET (como sitei em meu primeiro post), mesmo usando de Interfaces não consigo ver uma solução para isso, caso eu queira realmente manter as coisas em Assemblies separados.
Olá luizaso,
Eu postei algo sobre esse problema de referências cíclicas do .NET em meu blog. Eu sempre vi isto como um problema de design, mas gostaria aber a opinião de vcs…
[]s
Mauricio_Linhares
Uma entidade com responsabilidades de persistencia é uma salada de conceitos. Ela pode continuar sendo uma Entity, mas ao meu ver, mal modelada. Afinal de contas, o repository esta aí pra isso …
Repositories não são a única forma de se modelar o acesso a fontes de dados, AR em linguagens “duras” como Java realmente é horrível (eu fiz uma vez usando introduções do AspectJ mas não me agradei muito do resultado não), mas quando você passa pra uma linguagem com menos burocracia AR deixa o código bem mais simples e ainda tem a vantagem de ser uma classe a menos, afinal os métodos do repositório são todos stateless, se transformam num monte de métodos estáticos na classe do AR.
Não acho que AR torne uma entidade mal modelada, até porque as implementações de AR que eu tive contato até agora são bem menos poluentes que os métodos comuns de persistência em Java como o uso de annotations.
C
cmoscoso1 like
Sim. Vc tb pode usar domain services pra isso e apesar de ser menos comum, até pode ser feito dentro da propria entity. O importante é que seja feito delegando ao repositorio.
luizaso:
Apenas para título de informação, se em meu projeto .NET eu decido manter em dois projetos diferentes os meus Repositories e meus Entities, crio um problema de referência, pois meu projeto Repositories precisa referênciar o projeto de Entities e o projeto de Entities, se precisar de um Repository, vai ter que referênciar Repositoreis, o que cria uma referência circular não aceita pelo .NET (como sitei em meu primeiro post), mesmo usando de Interfaces não consigo ver uma solução para isso, caso eu queira realmente manter as coisas em Assemblies separados.
Você pode separar seu dominio em diferentes projetos mas nao deve faze-lo utilizando criterios tecnicos como o tipo do objeto (entities, repositorios, services, …). Isso vai te levar a codigo com alto acoplamento e baixa coesao (vide Uncle Bob).
Eric Evans sugere que organizemos nosso dominio em modulos (pacotes em java e namespaces em .net) utilizando criterios conceituais do dominio, fazendo com que a estrtura de pacotes contribua para a UBIQUITOUS LANGUAGE.
Isso porque referencias cruzadas devem ser evitadas em todos os niveis, inclusive entre modulos.
Alessandro_Lazarotti
Lezinho, apenas para esclarecer, se eu tenho uma entity que possui seus próprios métodos CRUD, se esta chama o Repositório para se auto-persistir, ainda assim seria incorreto de acordo com sua visão, ter esses métodos em minha Entity?
Do meu ponto de vista você esta dando voltas desnecessárias. Um repositório armazena informações, correto? Por que colocar mais este método identico na entidade (os CRUDs)? Apenas para delegar para o repositório? Qual o ganho disso?
Uma entidade tenta representar algo de seu domínio, ela tem o comportamento pertinente a sí. Esta entidade é armazenada em algum lugar, um repositório de dados, que é outro objeto de negócio.
Se uma entidade faz uso de um repositório de dados em seu método de negócio, faz sentido ela solicitar a ajuda de um repositório. Contudo não faz sentido a entidade assumir o papel de um repositório de dados, atuando só como uma fachada, sendo que já existe um repositório pra isso (e tanto um como outro pertencem a mesma camada de negócio).
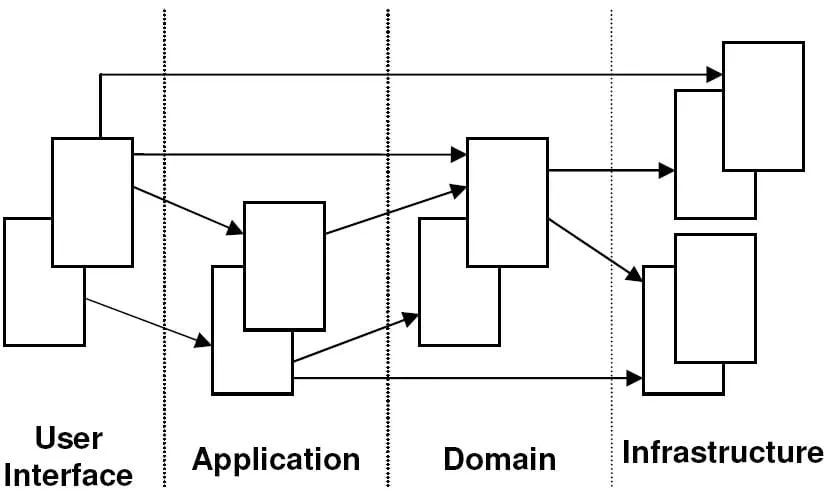
… isso faz mais sentido do que você sugeriu no princípio. Segue anexo o popular diagrama de uma “Layered Architecture” retirada do Domain-Driven Design. Veja que tanto a layer Application e até mesmo a UI pode acessar o domain, o que não se pode é o contrário (Repositório tbm é domain).
Uma entidade com responsabilidades de persistencia é uma salada de conceitos. Ela pode continuar sendo uma Entity, mas ao meu ver, mal modelada. Afinal de contas, o repository esta aí pra isso …
Repositories não são a única forma de se modelar o acesso a fontes de dados, AR em linguagens “duras” como Java realmente é horrível (eu fiz uma vez usando introduções do AspectJ mas não me agradei muito do resultado não), mas quando você passa pra uma linguagem com menos burocracia AR deixa o código bem mais simples e ainda tem a vantagem de ser uma classe a menos, afinal os métodos do repositório são todos stateless, se transformam num monte de métodos estáticos na classe do AR.
Não acho que AR torne uma entidade mal modelada, até porque as implementações de AR que eu tive contato até agora são bem menos poluentes que os métodos comuns de persistência em Java como o uso de annotations.
Concordo que é uma classe a menos, Mauricio, mas temos que ponderar se isso é ganho ou não. Repositório é tbm classe de negócio, tão quanto é uma entidade, eu acredito nesse valor agregado.
É claro que tbm se deve preservar o bom senso. Jamais iria ingorar AR usando RoR simplesmente por achar que o design fica melhor separando mais responsabilidades.
C
cmoscoso
Lezinho:
Maurício Linhares:
Repositories não são a única forma de se modelar o acesso a fontes de dados, AR em linguagens “duras” como Java realmente é horrível (eu fiz uma vez usando introduções do AspectJ mas não me agradei muito do resultado não), mas quando você passa pra uma linguagem com menos burocracia AR deixa o código bem mais simples e ainda tem a vantagem de ser uma classe a menos, afinal os métodos do repositório são todos stateless, se transformam num monte de métodos estáticos na classe do AR.
Não acho que AR torne uma entidade mal modelada, até porque as implementações de AR que eu tive contato até agora são bem menos poluentes que os métodos comuns de persistência em Java como o uso de annotations.
Concordo que é uma classe a menos, Mauricio, mas temos que ponderar se isso é ganho ou não. Repositório é tbm classe de negócio, tão quanto é uma entidade, eu acredito nesse valor agregado.
É claro que tbm se deve preservar o bom senso. Jamais iria ingorar AR usando RoR simplesmente por achar que o design fica melhor separando mais responsabilidades.
Repositorio nao é um ojbeto de negocio tanto quanto uma entidade. Sim, ele deve aderir a UBIQUITOUS LANGUAGE por conveniencia ja que reside no dominio mas nao tem o papel de “expressar o modelo”. Seu papel, assim como Factories é atuar no gerenciamento de ciclos de vida complexos que precisam ser encapsulados. Ciclos de vida dos “reais” objetos de dominio.
Portanto, outras solucoes como uma implementacao de AR decente sao muito bem vindas para substituir repositorios.
Alessandro_Lazarotti
Um repositório, diferente de uma factory, tem sentido real. É fatídico que as informações do negócio devem ser armazendas em algum repositório de dados, isso faz parte do core business, assim como a recuperação destes objetos. Este lugar de armazenamento é o repositório… o negócio tem conhecimento disso.
A Factory é um simples artifício de criação, irrelevante para o negócio.
luizaso
Já tinha me esquecido como aqui no GUJ uma pequena solicitação de informação pode se transformar em uma verdadeira aula sobre o assunto.
Laércio,
realmente concordo com você, e ontém mesmo estava pensando como essa separação por projetos pode não fazer muito sentido, isso vem de influências que sofro todos os dias na empresa onde trabalho. Mas ao ler seu artigo tive mais embasamento pra chegar a conclusão que minha idéia ontém de manter todos os elementos de um determinado assunto do meu modelo de domínio em um único projeto, fazendo agrupamento destes elementos pela utilização de namespaces, é a mais adequada para meu caso, o que foi também confirmado pelas afirmações feitas pelo Lezinho.
Posso dizer a vocês com certeza que aprendi mais sobre DDD neste e em outros tópicos do GUJ relacionados ao assunto do que havia aprendido durante muito tempo sofrendo as influências erradas em meu emprego.
Estou correndo atraz de todos os livros que foram me dado de referência, vai demorar pra ler todos, mas vai valer a pena.
Muito obrigado e continuo acompanhando o tópico, pois pelo que estou percebendo ainda vem mais opiniões e discussões sadias em cima das questões que levantei neste tópico, por ai.
Mauricio_Linhares
Num dos meus casos aqui terminei criando um repositório depois que o AR estava cheio demais de métodos de consulta, mas se não fosse isso, eu não teria utilizado repositórios. Acho que como forma de se separar as implementações ele é realmente muito importante, mas é extremamente simples assumir que a classe é o seu próprio repositório.
A instância não perde a sua identificação de entidade, mas a classe, que era “inútil” agora ganhou uma utilidade, ser a fonte das instâncias (dentro da linguagem ela já é isso, mas isso é outra história). O repositório continua existindo, só que agora ele não é uma classe separada, sem estado e que possívelmente vai ficar sendo injetada por alguma entidade externa.
Alessandro_Lazarotti
Não entendi quando você diz que a classe era “inútil” Maurício. Normalmente em uma modelagem rica as entidades possuem seus comportamentos de negócio (não estou me referindo a CRUD), por isso não deveria ser anêmica mesmo sem usar AR.
Contudo, o que você disse sobre ActiveRecord é algo que Fowler retratou em PoEAA… com o tempo vai se inchando, e há isso ele atribui sua utilização mais conjunta em projetos com Transaction Script do que com Domaim Model.
Mauricio_Linhares
A classe é inútil no sentido da sua definição estática (métodos estáticos), os comportamentos da entidade estão em seus métodos de instância.
Não acho, na verdade eu vejo isso como sendo algo bem incomum, dos diversos projetos que eu participei até hoje usando AR foi o único caso que isso realmente teve que ser feito, principalmente porque havia muita coisa de análise e mineração de dados, então eram coisas que não cabiam mesmo ali.
luizaso
Galera mais uma dúvida surgiu, na opinião de vocês, existe mesmo sentido em injetar o Repositório, quando necessário em Entities sendo que estes estão intrissicamente ligados em um determinado problema?
Qual seria o sentido desse nível de separação? Algum artigo bacana que justifique os ganhos dessa separação?
Valeu.
Mauricio_Linhares
luizaso:
Galera mais uma dúvida surgiu, na opinião de vocês, existe mesmo sentido em injetar o Repositório, quando necessário em Entities sendo que estes estão intrissicamente ligados em um determinado problema?
Qual seria o sentido desse nível de separação? Algum artigo bacana que justifique os ganhos dessa separação?
Valeu.
Rapaz, o problema é que é muito complicado de se injetar um repositório em uma entidade, especialmente se a entidade ainda não foi salva ou quando ela é na verdade uma entidade relacionada a a entidade principal que foi carregada do seu repositório.
Normalmente quando você precisa de alguma coisa assim, é mais fácil recorrer a um serviço que ligue o(s) repositório(s) a(s) entidade(s).
luizaso
Bacana Maurício, no seu comentário você diz…
Ou seja, se eu chegar a conclusão que não há a necessidade de utilizar injeção de dependência para utilizar meu repositório em minha entidade, não estarei quebrando uma regra de DDD, certo?
Mauricio_Linhares
Não vejo problema nenhum nisso.
Alessandro_Lazarotti
Mauricio Linhares:
A classe é inútil no sentido da sua definição estática (métodos estáticos), os comportamentos da entidade estão em seus métodos de instância.
Pois é, contra isso não tem mesmo o que eu dizer, é uma opção de design com seus prós e contras.
Eu sinceramente acredito que se faz uma melhor coesão sem os métodos estáticos na classe da entidade. Opto por um repositório separado, abstraído por uma interface, que me facilite entre outras coisas a execução de testes, além de ajudar na legibilidade.
//uma opcaoList<Aluno>alunosEmDebito=Aluno.obtemAlunosEmDebito();//acho essa mais legivelList<Aluno>alunosEmDebito=repositorioAluno.obtemAlunosEmDebito();
Alessandro_Lazarotti
luizaso:
Bacana Maurício, no seu comentário você diz…
Ou seja, se eu chegar a conclusão que não há a necessidade de utilizar injeção de dependência para utilizar meu repositório em minha entidade, não estarei quebrando uma regra de DDD, certo?
Galera mais uma dúvida surgiu, na opinião de vocês, existe mesmo sentido em injetar o Repositório, quando necessário em Entities sendo que estes estão intrissicamente ligados em um determinado problema?
Qual seria o sentido desse nível de separação? Algum artigo bacana que justifique os ganhos dessa separação?
Valeu.
Rapaz, o problema é que é muito complicado de se injetar um repositório em uma entidade, especialmente se a entidade ainda não foi salva ou quando ela é na verdade uma entidade relacionada a a entidade principal que foi carregada do seu repositório.
Normalmente quando você precisa de alguma coisa assim, é mais fácil recorrer a um serviço que ligue o(s) repositório(s) a(s) entidade(s).
Uma factory pode ajudar neste sentido.
[]s
Mauricio_Linhares
Uma factory que cria o repositório? E quem injeta a factory na entidade?
Aí ficamos com a história do ovo e da galinha.
luizaso
Em relação a isso, o como implementar é até tranquilo, no caso como meu projeto é em .NET, utilizo o Castle Windsor para implementar IoC / DI.
Agora a grande motivação para se injetar um Repositório em uma Entity, seria Testes Unitários, estou certo?
Abraços.
Mauricio_Linhares
Lezinho:
Eu sinceramente acredito que se faz uma melhor coesão sem os métodos estáticos na classe da entidade. Opto por um repositório separado, abstraído por uma interface, que me facilite entre outras coisas a execução de testes, além de ajudar na legibilidade.
//uma opcaoList<Aluno>alunosEmDebito=Aluno.obtemAlunosEmDebito();//acho essa mais legivelList<Aluno>alunosEmDebito=repositorioAluno.obtemAlunosEmDebito();
Eu já acho a primeira bem mais legível, além de conter menos símbolos a serem lembrados, em vez de eu saber que tem uma interface de repositório e uma implementação, eu tenho apenas a classe que eu estou buscando.
Eu vejo que repositórios tem seu uso em sistemas que precisam ser independentes de bancos de dados ou que precisam suportar diversos bancos de dados com instruções ou modos de trabalho diferentes, fora isso eu não consigo ver vantagem em utilizá-los no dia a dia.
Mas é uma questão de ponto de vista, basicamente os dois conseguem resolver o problema ao qual se propoem, escolher um ou o outro vai da cabeça de quem estiver desenvolvendo a solução.
Alessandro_Lazarotti
Aspecto nele :twisted:
Mauricio_Linhares
Não vejo relacionamento entre uma coisa e outra.
Laercio_Queiroz
Uma factory que cria o repositório? E quem injeta a factory na entidade?
Aí ficamos com a história do ovo e da galinha.
Oi Maurício,
Penso na factory criando a entidade e injetando o repositório.
[]s
Mauricio_Linhares
Vixe, que complicação.
Serviços fazem o trabalho de forma bem mais simples.
Mauricio_Linhares
Só complementando, vai da cabeça e do martelo de quem está implementando, fazer AR em Java não é lá muito simples não.
Laercio_Queiroz
Vixe, que complicação.
Serviços fazem o trabalho de forma bem mais simples.
hehehe,… ai vai depender do contexto. A factory é uma das opções, IMO bem simples de compreender.
[]s
luizaso
Maurício,
o que quiz dizer, é que quando você acessa um repositório por uma interface, separando sua implementação e injetando essa de alguma forma, seja factory ou aspéctos, você tem a vantagem de depois poder criar um repositório fake quando for fazer os seus testes.
Claro que você sempre pode usar Mocks, mas se já tiver um repositório fake implementado, acaba que consegue ter a vantagem de reaproveita-lo e diminuir a quantidade de códigos no momento de criar os testes unitários.
Bom na verdade eu ainda estou procurando a real vantagem de se utilizar DI, para injetar meus repositórios em minhas entidades, essa vantagem ainda não ficou clara pra mim.
Leozinho,
infelizmente aspéctos não são tão realidade no mundo .net quanto são em java.
Mauricio_Linhares
Mas é exatamente por isso que eu não entendi, isso é a vantagem básica se se usar DI em qualquer coisa, não é específica desse caso.
De qualquer forma, eu acho complicado injetar repositórios em entidades, serviços são mais simples de se utilizar e manter.
luizaso
Maurício, eu citei um exemplo desta vantagem de se usar DI, claro que existem outros muitos, só queria alguns de referência para apoiar minha decisão arquitetural em minha aplicação.
Outra dúvida, desculpe a minha ignorância, mas o que são esses Serviços citados por você como vantagem sobre o uso de DI.
Valeu!!!
Laercio_Queiroz
Mas é exatamente por isso que eu não entendi, isso é a vantagem básica se se usar DI em qualquer coisa, não é específica desse caso.
De qualquer forma, eu acho complicado injetar repositórios em entidades, serviços são mais simples de se utilizar e manter.
Se o servico fizer sentido no domínio eu concordo contigo. Mas nos casos onde a entidade é quem deve fornecer as informações e precisa do repositório para isso, não vejo muito sentindo em implementar esta operação em outro lugar e tirar essa responsabilidade da entidade.
[]s
luizaso
Maurício e outros, por favor, ignorem a minha pergunta sobre serviços acima, desculpem, foi falta de atenção.
Alessandro_Lazarotti
Maurício Linhares:
Eu vejo que repositórios tem seu uso em sistemas que precisam ser independentes de bancos de dados ou que precisam suportar diversos bancos de dados com instruções ou modos de trabalho diferentes, fora isso eu não consigo ver vantagem em utilizá-los no dia a dia.
Quem lhe dá independência de banco de dados é o DAO, não o Repository.
Pra mim a função do repositório é mesmo uma função de domínio.
Aproveitando meu exemplo anterior, veja o código abaixo:
// um metodo de negócio para o repositorioList<Aluno>alunosEmDebito=repositorioAluno.obtemAlunosEmDebito();...//um metodo de negócio para o Alunoaluno.agendaAvaliacao(avaliacaoSubstitutiva).paraData(dataDaAvaliacao);
A linguagem é clara e distingue bem os deveres do repositorio e da entidade. Utilizando métodos estáticos na entidade para agir como repositório, essa divisao de responsabilidade não ficaria tão clara (Aluno.obtemAlunosEmDebito()), além de dificultar os testes unitários.
Maurício Linhares:
Só complementando, vai da cabeça e do martelo de quem está implementando, fazer AR em Java não é lá muito simples não.
Isso é verdade. Como já disse, se o sistema esta sendo desenvolvido em RoR, seria besteira não utilizar AR (ignorar uma funcionalidade que esta alí de graça por "particularidades de design", não parece ser uma escolha muito sensata). Já fazer isso em Java, é tão insensato o quanto.
C
cmoscoso
Lezinho:
Um repositório, diferente de uma factory, tem sentido real. É fatídico que as informações do negócio devem ser armazendas em algum repositório de dados, isso faz parte do core business, assim como a recuperação destes objetos. Este lugar de armazenamento é o repositório… o negócio tem conhecimento disso.
A Factory é um simples artifício de criação, irrelevante para o negócio.
Eu sei que o topico nao é sobre factories mas gostaria de esclarecer alguns pontos.
Factories encapsulam a criacao complexa de alguns objetos de dominio. Você pode delegar à factories a reconstituicao de objetos ja persistidos, não é só criacao de novos objetos. E um dominio pode nao precisar armazenar informacoes, assim como nem todo dominio possui agregados complexos que justifiquem factories. Um “sentido real” para cada conceito é relativo, depende de cada caso.
Outra coisa, não faz parte do core business que as informacoes devam ser armazenadas no repositorio de dados. Faz parte sim de algum core business que uma mesma conta bancaria criada agora deve ser acessível posteriormente. Essa existencia atraves de diferentes ciclos de vida é o que define o conceito de entidade.
Factories e repositorios sao utilizados para suportar ciclos de vida dos objetos de dominio, ambos sao irrelevantes para o negocio.
Alessandro_Lazarotti
cmoscoso:
Outra coisa, não faz parte do core business que as informacoes devam ser armazenadas no repositorio de dados. Faz parte sim de algum core business que uma mesma conta bancaria criada agora deve ser acessível posteriormente. Essa existencia atraves de diferentes ciclos de vida é o que define o conceito de entidade.
Factories e repositorios sao utilizados para suportar ciclos de vida dos objetos de dominio, ambos sao irrelevantes para o negocio.
É de total relevância para a conta bancária informações sobre o rendimento total de uma determinada poupança em um período. Essa consulta faz parte do negócio e tem valor p/ o cliente, inclusive essa é a linguagem natural que ele usa.
Como ele é buscado na infra, não interessa, um DAO ou outro meio me retorna isso, mas essa funcionalidade de extração da informação é de grande importância. A assinatura deste método de busca de dados, tem que ser ubiquitous e conhecida pelo especialista do domínio e pela equipe de desenvolvimento.
A relevância da factory é mais branda. Um repository pode utilizar uma factory para montar uma informação, mas isso não é lá tão transparente para o negócio, mesmo sendo necessário para o domínio.
Mauricio_Linhares
Quem dá independência de banco de dados é uma abstração ao acesso a fontes de dados, como um repositório. Não é possível conseguir independência de bancos de dados em um AR porque não existe um AR sem um banco de dados. Não entendi o que o DAO tem haver com isso na história.
Não consigo ver qual o problema de clareza em Aluno.obtemAlunosEmDebito() se comparado ao repositório, ambos passam a mesma idéia. Sobre testes unitários, ARs também não dificultam em nada, você tem algum exemplo aonde um AR torne testes unitários mais complexos?
O repositório vem para servir o domínio como uma coleção de objetos vivos em memória. Quem mascara o acesso é um DAO ou outro meio. Eu costumo ter uma interface DAO como componente de meus repositórios:
publicclassRepositorioAlunoImplimplementsRepositorioAluno{@InprivateDataAcessObjectdao;publicvoidadiciona(Alunoaluno){//pode realizar alguma rotina comum //ao objeto 'aluno' antes de persistir seu estado....dao.persiste(aluno);}}
Esta é ‘uma’ possível implementação.
O repositório atua como mediador entre o domínio(onde ele esta) para a persistence layer onde esta o DAO, quase sempre, DataMapper (conforme indicação do padrão). Sua afirmação anterior de que:
… é mais focada no DAO, na infra, e não no Repository.
Alessandro_Lazarotti
A instrução Aluno.obtemAlunosEmDebito não é clara para o domínio. Os alunos em débito habitam onde? Em “Aluno”? Aluno é um tipo e não uma caixa que armazena dados. Essa é a diferença.
Quanto aos testes, “obtemAlunosEmDebito” com AR da forma descrita anteriormente é um dado estático, imutável (em Java). Caso você tiver em mãos ponteiros de métodos, não tem problema, caso contrário criar uma interface repositório se torna uma saída bem mais interessante de se implementar objetos falsos.
Bom, esta é uma visão que tenho (com vista no que tenho olhado por aí), pois nunca implantei em Java AR para dizer mais sobre testes unitários com estes. Inclusive estou curioso para saber qual seria uma saída boa para isso.
pcalcado
Como eu disse antes essa é uma discussõa que está misturando coisas completamente diferentes. Uma coisa é como seu Domain Model vê persistência (seja com Repository ou não) outra coisa é como persistência é implementada (AR ou DM). Pode ser mais natural pensar em um Repositório acessando/sendo implementado por um DataMapper mas nada impede que um Repositório acesse/seja implementado por um Active Record. Para quem trabalha com Java é provavelmente mais difícil porque a linguagem adiciona tanto ruído sintático que não dá para ter Active Records limpos mas em plataformas como Ruby isso não é verdade.
Resumindo:
Não é preciso ter Repository (ou qualquer outro padrão) para ter Domain-Driven Design
Um Repository pode abstrair qualquer implementação/estratégia de persistência, o domain model não está nem aí para isso
C
cmoscoso
Se tem valor pro negocio deverá ser implementado no dominio, mas não é requisito de nenhum negocio que seja feito por meio de repositorios.
A implementacao de repositorios é sempre transparente para o negocio, pelo menos deveria ser. De qualquer forma, eu ja vi factories utilizando repositorios, nao o contrario.
Alessandro_Lazarotti
Diferentes porém necessárias e relevantes. Isolamento do domínio e abstração da infraestrutura fazem parte de qualquer modelagem de sistema q queira ser desenhada com DDD.
pcalcado:
Não é preciso ter Repository (ou qualquer outro padrão) para ter Domain
Driven Design
Com certeza, inclusive é isto que eu estava defendendo a pouco em outro tópico. Para ter Domain-Driven você precisa retratar o domínio em espécie e comportamento. O design proposto também preza pelo isolamento deste domínio, abstraindo a infraestrutura. Implementar Active Record em Java não ajuda em nenhum destes requisitos.
Como você, o Maurício e eu tbm concordo, Active Record em Java não é uma estratégia natural(seria muito intrusivo no modelo, o que não é a realidade em Ruby).
Uma coisa que não entendi e realmente gostaria de entender foi a colocação:
Como implementar ‘repositório’ com AR? Como abstrair em um modelo estático o que de fato é o Active Record? A não ser que a linguagem lhe dê subsídios dinâmicos, não vejo como fornecer esta abstração.
O repositório vem para servir o domínio como uma coleção de objetos vivos em memória. Quem mascara o acesso é um DAO ou outro meio. Eu costumo ter uma interface DAO como componente de meus repositórios:
publicclassRepositorioAlunoImplimplementsRepositorioAluno{@InprivateDataAcessObjectdao;publicvoidadiciona(Alunoaluno){//pode realizar alguma rotina comum //ao objeto 'aluno' antes de persistir seu estado....dao.persiste(aluno);}}
Esta é ‘uma’ possível implementação.
O repositório atua como mediador entre o domínio(onde ele esta) para a persistence layer onde esta o DAO, quase sempre, DataMapper (conforme indicação do padrão). Sua afirmação anterior de que:
Quem mascara o acesso a uma fonte de dados é o repositório, se você está usando um DAO dentro do repositório, é uma opção de implementação sua, não existe problema nenhum da própria implementação do repositório fazer acesso ao banco de dados/mecanismo de persistência não. No DDD mesmo (o livro) os repositórios de rodam o SQL direto, não usam mais ninguém no meio pra fazer isso não. Não vejo porque misturar DAOs e repositórios, quando ambos fazem a mesma coisa, eles só tem “idéias” diferentes.
C
cmoscoso
Você diria o mesmo em relacao a model-driven-design?
Mauricio_Linhares
Tem certeza? Porque ele não pode armazenar os dados se pra criar um aluno eu tenho que fazer um “Aluno.new” (em Ruby, por exemplo) ?
A implementação da sua interface para testes vai ser tão falsa quanto os meus métodos estaticos mockados.
pcalcado
Não são relevantes, não nesta discussão. Desde que você abstraia a implementação pouco importa como ela é feita.
Lezinho:
Como implementar ‘repositório’ com AR? Como abstrair em um modelo estático o que de fato é o Active Record? A não ser que a linguagem lhe dê subsídios dinâmicos, não vejo como fornecer esta abstração.
Numa linguagem de tipagem estática meia-bomba como Java você pode fazer o Repository delegar para o AR ou o AR implementar o Repository (no caso é melhor ter também uma interface só com os métodos do objeto de negócio).
pcalcado
cmoscoso:
Você diria o mesmo em relacao a model-driven-design?
Mais ainda. Você sequer precisa de DDD para ter MDD.
C
cmoscoso
pcalcado:
cmoscoso:
Você diria o mesmo em relacao a model-driven-design?
Mais ainda. Você sequer precisa de DDD para ter MDD.
Veja, nao estou falando de Model-Driven-Development.
Alessandro_Lazarotti
cmoscoso:
Se tem valor pro negocio deverá ser implementado no dominio, mas não é requisito de nenhum negocio que seja feito por meio de repositorios.
Mas repositório é domínio … e se ele cuida da recuperação de objetos, não vejo porque não estar nele.
Repositório pode conter lógica, não apenas buscar dados de forma bruta e restaurar da mesma forma para seu solicitante. Por isso, um repositório pode sim (mas não obrigatoriamente), conter factories que auxiliem a montar, por exemplo, um coleção de objetos modificados. Não existe restrição quanto a isso.
pcalcado
Model-Driven Design é uma parte de Model-Driven Development. Basicamente significa que você vai ter o modelo como guia principal do seu projeto e você não precisa usar DDD para usar o modelo como cerne do seu design.
C
cmoscoso
Eu nao disse que repositorios nao podem utilizar factories, eu disse que ainda nao vi sendo utilizado dessa maneira, mas o ponto é que nao importa para o negocio como o repositorio sera implementado.
Ou seja, IMHO repositorios nao devem conter regras de negocio.
Alessandro_Lazarotti
Sim, o que mostrei é UMA implementação… por isso coloquei o ‘uma’ entre aspas no post. Ja tive muito ganho nesta separação centralizando o acesso em único ponto (quando por exemplo mudei fecthMode de todo o projeto, e tive que controlar todos os pontos de flush da persistência). Se não tivesse canalizado a persistência, teria que refatorar todos meus repositórios. Isso é um exemplo do pq dividir bem as responsabilidades de DAOs e Repositorios (isso é opinião, em nenhum momento quero afirmar que isso tem que ser assim).
Mauricio_Linhares
Uma dúvida nadas haver agora, você faz flush manualmente no DAO?
R
ronildobraga
Lezinho:
publicclassRepositorioAlunoImplimplementsRepositorioAluno{@InprivateDataAcessObjectdao;publicvoidadiciona(Alunoaluno){//pode realizar alguma rotina comum //ao objeto 'aluno' antes de persistir seu estado....dao.persiste(aluno);}}
Estou acompanhando a conversa de vocês desde o inicio, porem fiquei com uma duvida com o código acima.
Como vc fez esta implementação de repository usando a anotação @In ?
Eu estou imaginando que vc tenha 1 interface e 2 classes: RepositorioAluno, RepositorioAlunoImpl, DataAcessObject
Apesar da classe se chamar DataAcessObject creio que ela na verdade deveria se chamar AlunoDAO
Imagino que vc esta injetando(@In) o DAO na sua implementação do Repository do Aluno para não criar uma fábrica, caso seja verdade, vc poderia dar mais detalhes de como vc fez essa injeção ? Como o DAO recebe o EntityManager para persistir a entidade ?
Alessandro_Lazarotti
Sim. Fazendo isso em Ruby você esta criando um novo objeto do tipo Aluno e não o recuperando. Um tipo cria instâncias do seu tipo, normal… Um repositório não busca necessariamente informações apenas no seu tipo, já que um prática é te-lo apenas para Entities Roots.
Você utiliza mock para método estático? Qual framework vc utiliza(é que realmente eu nunca precisei utilizar desta forma).
Alessandro_Lazarotti
Uma dúvida nadas haver agora, você faz flush manualmente no DAO?
Sim, foi necessário Maurício. O projeto utilizava transação otimista, com o flushMode em auto e a transação sendo gerenciada pelo Seam da duração de uma requisição. Contudo, quando se utilizava Ajax e o modelo do faces era atualizado, aquele XMLRequest descarregava no banco a alteração (o que não era o esperado).
Alessandro_Lazarotti
ronildo braga:
Estou acompanhando a conversa de vocês desde o inicio, porem fiquei com uma duvida com o código acima.
Como vc fez esta implementação de repository usando a anotação @In ?
Eu estou imaginando que vc tenha 1 interface e 2 classes: RepositorioAluno, RepositorioAlunoImpl, DataAcessObject
Apesar da classe se chamar DataAcessObject creio que ela na verdade deveria se chamar AlunoDAO
Imagino que vc esta injetando(@In) o DAO na sua implementação do Repository do Aluno para não criar uma fábrica, caso seja verdade, vc poderia dar mais detalhes de como vc fez essa injeção ? Como o DAO recebe o EntityManager para persistir a entidade ?
A Anoatação @In, é a maneira que o Seam faz DI. No código citado, eu injeto RepositorioAlunoImpl em RepositorioAluno e DataAcessObjectImpl (ou implementações específicas) no dao.
o 'dao' de maneira alguma é algo do tipo "AlunoDAO". Ele contém, por exemplo, o entityManager e métodos de pesquisas não especialistas. Ele faz todo o controle da infra:
Um exemplo de sua interface:
public interface DataAccessObject {
public abstract void queryUpdate(String queryString);
public abstract List query(String queryString);
public abstract void queryUpdate(String queryString,Map<String, Object> namedParameters);
public abstract List query(String queryString,Map<String, Object> namedParameters);
public abstract void queryUpdate(String queryString, Object[] params);
public abstract List query(String queryString, Object[] params);
public abstract void persist(Object obj);
public Object saveOrUpdate(Object obj);
public abstract void remove(Object obj);
(...)
}
... o repositório da a alma para a consulta. Este tipo de implementação me agrada pela flexibilidade que se tem nas camadas.
Alessandro_Lazarotti
Em minha opinião ele tem que ter, afinal de contas ele faz parte do domínio.
Mauricio_Linhares
Sim. Fazendo isso em Ruby você esta criando um novo objeto do tipo Aluno e não o recuperando. Um tipo cria instâncias do seu tipo, normal… Um repositório não busca necessariamente informações apenas no seu tipo, já que um prática é te-lo apenas para Entities Roots.
Opa, um repositório deveria buscar apenas o root, se você precisa de alguma coisa que está na agregação tem que pegar o root e do root acessar o agregado, não?
Esqueça Java homem
Enfim, o que eu estou tentando dizer é que, objeto falso por objeto falso, ambos fazem a mesma coisa, tanto a interface mockada como os métodos estáticos mockados. E eu nunca fiz isso em Java não, mas se fosse fazer eu acho que precisaria de algumas mágicas com o AspectJ.
C
cmoscoso
C
cmoscoso
Lezinho:
Em minha opinião ele tem que ter, afinal de contas ele faz parte do domínio.
Se lesse meus posts nessa thread direcionados a você perceberia o que estou tentando lhe dizer. Existem certos objetos de dominio que possuem outras responsabilidades (de suporte) que nao a de expressar o modelo de negocio.
Alessandro_Lazarotti
cmoscoso:
Lezinho:
Mas repositório é domínio …
Normalmente em uma modelagem conceitual, você não define factories e repositories. Dado a isso, de fato eles não são criados pelo domínio e sua natureza, embora pertença a ele implícitamente.
A citação diz isso:
“do not themselves come from the domain”
… um cliclo de vida depende dos critérios exigidos pelo domínio.
Alessandro_Lazarotti
mauricio linhares:
Opa, um repositório deveria buscar apenas o root, se você precisa de alguma coisa que está na agregação tem que pegar o root e do root acessar o agregado, não?
Imagine um objeto ‘produto’ e outro ‘caracteristica’, onde produto cotem um colecao da entidade fraca chamada caracteristica.
Você precisa apresentar na tela todas as caracteristicas, para poder atribui-la a um produto. Quem faz a consulta retornando todas as entidades fracas “caracteristica” que ira compor um produto?
O exemplo de código que escrevi, o qual debatemos, era Java, não era?
Mauricio_Linhares
Lezinho:
Imagine um objeto ‘produto’ e outro ‘caracteristica’, onde produto cotem um colecao da entidade fraca chamada caracteristica.
Você precisa apresentar na tela todas as caracteristicas, para poder atribui-la a um produto. Quem faz a consulta retornando todas as entidades fracas “caracteristica” que ira compor um produto?
Bem, não entendi bem o seu exemplo, mas se característica é uma “entidade fraca” ela não deve existir sem um produto e tecnicamente não dá pra chegar nela sem um produto, dá? O produto já vem que vir com as suas características carregadas.
Eu estou discutindo conceitos, se você quer discutir a implementação em Java (que eu já repeti diversas vezes que é complicada) é outra história. Estamos falando de coisas diferentes então.
C
cmoscoso
Lezinho:
Normalmente em uma modelagem conceitual, você não define factories e entities. Dado a isso, de fato eles não são criados pelo domínio e sua natureza, embora pertença a ele implícitamente.
A citação diz isso:
“do not themselves come from the domain”
… um cliclo de vida depende dos critérios exigidos pelo domínio.
Onde você disse entities creio que seria repositorios…
Mas mesmo assim nao entendi nada do que você escreveu, muito menos relacionar com regras de negocio em repositorios que era o meu ponto. :?
Alessandro_Lazarotti
Mas eu estou criando um novo produto e tenho que selecionar características para atribuir a este.
Um produto é composto de características, depois de criado, o que você disse é verdade. Mas primeiro eu preciso criar este novo objeto …
mauricio linhares:
Eu estou discutindo conceitos, se você quer discutir a implementação em Java (que eu já repeti diversas vezes que é complicada) é outra história. Estamos falando de coisas diferentes então.
É, existe uma confusão em nossa conversa. O tempo todo eu tbm disse que se fosse em Ruby, usaria AR sem pestanejar. Quando coloquei o código em java, achei estranho você dizer que não teria problemas para realizar testes no método estático, foi isso.
Mauricio_Linhares
Lezinho:
Mas eu estou criando um novo produto e tenho que selecionar características para atribuir a este.
Um produto é composto de características, depois de criado, o que você disse é verdade. Mas primeiro eu preciso criar este novo objeto …
Continuo sem entender. As características já existiam no banco de dados antes do produto existir?
Alessandro_Lazarotti
cmoscoso:
Onde você disse entities creio que seria repositorios…
Mas mesmo assim nao entendi nada do que você escreveu, muito menos relacionar com regras de negocio em repositorios que era o meu ponto
Eita, escrevi errado, já esta editado.
Não entendi o que você não entendeu (fora minha palavra trocada), mas tudo bem.
O que não sei onde não fui claro é que métodos do tipo: buscaRendimentoAprovado faz total parte do negócio, isso não é visível pra você?
Alessandro_Lazarotti
Maurício Linhares:
Lezinho:
Mas eu estou criando um novo produto e tenho que selecionar características para atribuir a este.
Um produto é composto de características, depois de criado, o que você disse é verdade. Mas primeiro eu preciso criar este novo objeto …
Continuo sem entender. As características já existiam no banco de dados antes do produto existir?
Sim
Mauricio_Linhares
E como é que elas são entidades fracas?
Se elas existem e são buscadas sem o aggregate, deveriam ter um repositório só pra elas.
C
cmoscoso
Faz parte do negocio ao aderir à UBIQUITOUS LANGUAGE. Mas estou falando de regras de negocio e assinaturas de metodos nao possuem regras de negocio, nem a implementacao de buscaRendimentoAprovado caso este seja um metodo de repositorio.
editado: concluindo, repositorios vivem no dominio, se expressam em termos da ubiquitous language, mas nao devem conter regras de negocio em sua implementacao.
Mauricio_Linhares
Carlos, o repositório tem conhecimento de negócio a partir do momemto que ele representa a regra de se “conhecer um rendimento aprovado”, ter um rendimento em estado de aprovado é uma coisa do negócio, que é representado nas regras do negócio do mundo real e foi transposto para um método de consulta do repositório.
C
cmoscoso
Maurício Linhares:
Carlos, o repositório tem conhecimento de negócio a partir do momemto que ele representa a regra de se “conhecer um rendimento aprovado”, ter um rendimento em estado de aprovado é uma coisa do negócio, que é representado nas regras do negócio do mundo real e foi transposto para um método de consulta do repositório.
Se o que você chama de regra de negocio é construir uma query que procura na coluna STATUS da tabela RENDIMENTOS pelo valor “APROVADO”, esta perfeito!
Mas isso na real nao é regra de negocio mas sim infraestrutura de persistencia e bancos de dados nao armazenam regras de negocio.
Mauricio_Linhares
E como é que você sabe que é apenas isso? Será que é sempre assim? Eles nunca tem conhecimentos de nada do negócio?
Num dos últimos sistemas que eu trabalhei, o site fazia recomendações de produtos aos usuários com base no que o usuário tinha visto ou navegado, se isso não é regra de negócio também eu não sei mais o que é.
pcalcado
Moscoso, eles não vêm do domínio, no sentido que não existem no mundo real geralmente não existem repositórios, mas eles são parte do domain model.
C
cmoscoso
E como é que você sabe que é apenas isso? Será que é sempre assim? Eles nunca tem conhecimentos de nada do negócio?
Num dos últimos sistemas que eu trabalhei, o site fazia recomendações de produtos aos usuários com base no que o usuário tinha visto ou navegado, se isso não é regra de negócio também eu não sei mais o que é.
A regra de negocio esta em como são colhidas as informacoes do usuario, baseado na sua interacao com o site, e na forma de recomendar os produtos de acordo com as informacoes obtidas. O papel do repositorio é secundario.
Na maioria das vezes objetos de negocio recorrem a repositorios para consultas simples. Outras vezes pode ser util infiltrar objetos de negocio no repositorio atraves de parametros da sua interface. Assim a regra de negocio continua encapsulada e deixa o repositorio livre pra implementar infraestrutura.
C
cmoscoso
Exato! Geralmente nao existe o conceito de repositorios no dominio a ser modelado. Quando usamos repositorios no dominio ele ja tem uma responsabilidade atribuida.
C
cmoscoso
Eu editei esse post em que citei o livro pra deixar mais claro o contexto da discussao. Eu nao quis dizer que não é dominio, apenas que eles ja têm responsabilidades pre-estabelecidas, independente de qual seja o dominio.
Apesar de nao ser um pecado capital ter regras de negocio em repositorios eu procuro evitar, você nao?
Alessandro_Lazarotti
Maurício Linhares:
E como é que elas são entidades fracas?
Se elas existem e são buscadas sem o aggregate, deveriam ter um repositório só pra elas.
Não são apenas Root Entities que podem ser persistidos. Entidades menores e até mesmo Value Objects podem ter seu estado persistido. Apenas os elementos roots devem ser recuperados do repositório de forma a fazer parte do negócio, os outros devem ser acessados apenas mediante navegação da associação… beleza, estou de acordo com isso. Contudo, existem particulariedades que fazer um repositório apenas para recuperar uma listagem de todos objetos de valor, que são utilizados exclusivamente para uma associação específica em um root, acaba sendo burocrático demais …
pcalcado
cmoscoso:
Apesar de nao ser um pecado capital ter regras de negocio em repositorios eu procuro evitar, você nao?
Não é nem evitar, qual regra um repositório teria? Eu não consigo lembrar de nenhum xemplo de cabeça onde criei um repositório com aluma regra, como eles não existem no mundo real (do domínio) não é natural que tenham regras.
C
cmoscoso
Mas as pessoas que eu converso sobre DDD a maioria nao ve problemas em colocar negocio ali, e geralmente fazem isso… nao há limites para a criatividade humana!
Eu mesmo ja quebrei muita cabeca para entender essa zona cinzenta que existe entre a interface do repositorio e a infraestrutura de fato. Porque a implementacao do repositorio nao é realmente camada de infraestrutura porque depende do dominio e nao parece natural na camada de domínio porque possui codigo de infraestrutura (SQL, DAO, entity manager).
tnaires
A implementação do repositório pertence à infraestrutura, e não ao domínio. O domínio só conhece a interface; a implementação é injetada de alguma forma na camada de negócios (containers DI, factories, aspectos, etc). Se a implementação do repositório contém X métodos a mais que a abstração, a camada de negócios não sabe nem que esses X métodos existem.
C
cmoscoso
tnaires:
A implementação do repositório pertence à infraestrutura, e não ao domínio. O domínio só conhece a interface; a implementação é injetada de alguma forma na camada de negócios (containers DI, factories, aspectos, etc). Se a implementação do repositório contém X métodos a mais que a abstração, a camada de negócios não sabe nem que esses X métodos existem.
Entao como você faz para implementar um metodo do repositorio que retorna um objeto da domain layer?
Rendimento buscaRendimentoAprovado();
Sua camada de infraestrutura faz um import do objeto de dominio Rendimento?
O simples fato de a implementacao (o que você diz ser camada de infraestrutura) implementar a interface (camada de dominio) ja viola principios basicos da arquitetura e separacao por camadas.
tnaires
cmoscoso:
Entao como você faz para implementar um metodo do repositorio que retorna um objeto da domain layer?
Rendimento buscaRendimentoAprovado();
Sua camada de infraestrutura faz um import do objeto de dominio Rendimento?
Ao meu ver, não há nenhum problema em um DAO por exemplo instanciar objetos da camada de domínio através de Factories. Mas posso estar errado.
Viola por quê? O repositório ( que é abstrato e não sabe nada de persistência - apenas declara os métodos de domínio ) pertence à camada de domínio, e a implementação ( que é concreta e conhece tudo de persistência ) pertence à infra-estrutura, num exemplo claro de inversão de dependências. O acoplamento depende de como você injetará a implementação ( um DAO, por exemplo ) na camada de domínio.
pcalcado
Moscoso, empilhamento de Camadas é algo interessante mas não é um requerimento. Quando Camadas são cross-cutting concerns como persistência, egurança ou distribuição é praticamente impossível (em java ao menos). No caso de persistência esqueça empilhamento, minha primeira mensagem nesta thread foi sobre isso: use Dependency Inversion Principle apenas.
C
cmoscoso
Eu já desencanei do isolamento total faz tempo, estava apenas comentando.
Mas eu gosto de ter a camada de insfraestrutura independente. Pra isso eu crio um modulo de infraestrutura de persistencia, e geralmente ele reside no namespace do dominio. É a tal área cinzenta que havia dito.
E DIP é lei, mas estou falando de camadas e camadas sempre serão empilhadas.
pcalcado
cmoscoso:
E DIP é lei, mas estou falando de camadas e camadas sempre serão empilhadas.
Nao. Alguns autores insistem em Camadas empilahdas mas isso nao eh umr equerimento par ausar o padrao. Camadas sao agrupamentos de componentes com responsabilidade relacionada apenas, podem ser opacas/empilhadas ou nao.
C
cmoscoso
pcalcado:
Nao. Alguns autores insistem em Camadas empilahdas mas isso nao eh umr equerimento par ausar o padrao.
Referências?
É porque “camadas não-empilhadas” me lembra módulos.
tnaires
Mas cmoscoso, você poderia dar um exemplo de sua “área cinzenta”? Fiquei curioso agora.
C
cmoscoso
com.exemplo.domain - regras de negocio/interface repositorios com.exemplo.domain.impl - depende de domain e infra
com.exemplo.infra - implementacoes jpa, hibernate, …
pcalcado
POEAA, pagina 17
C
cmoscoso
Creio que você esteja se referindo a esse trecho:
Se for, nem me esforçando consigo ver referencia a camadas nao-empilhadas.
pcalcado
cmoscoso:
Creio que você esteja se referindo a esse trecho:
Se for, nem me esforçando consigo ver referencia a camadas nao-empilhadas.
Pode ser problema do idioma.
Vamos lá:
POEAA:
When thinking of a system in terms of layers, you imagine the principal subsystems in
the software arranged in some form of layer cake, where each layer rests upon a lower
layer.
Quando você pensa nas Camadas de um sistema você imagina os principais subsistemas dispostas em Camadas, como num bolo onde as Camadas superiores icam em cima das inferiores.
Neste esquema as Camadas superiores usam os serviços das inferiores, mas as inferiores não estão cientes das superiores.
Então a Camada geralmente esconde suas inferiores de suas superiores
Nem todas as arquiteturas de Camadas são opacas como estas, mas a maioria é[…]
C
cmoscoso
Não pra mim e acho que pra você também não, considerando a sua traducao…
Vejamos (assumindo que a definicao de “opaco” seja de conhecimento do leitor):
Geralmente a camada 4 nao esta ciente da camada 2, portanto a camada 3 é opaca.
Nem sempre camadas são opacas, em algumas situacoes a camada 4 pode acessar a camada 2 diretamente, ou seja, a camada 3 é transparente.
pcalcado
Acho que o problema então é o conceito de empilhar. Eu usei o termo pela primeira vez em 2005-2006 e sinceramente não sei de onde tirei, acho que do Buschmann mas não estou com o livro em mãos. Todas as outras referências que tenho sequer falam em stacks -exceto pelo Larman que cita network stacks como exemplo de Camadas opacas/empilhadas.
Para mim você empilha Camadas quando faz uma depender da imediatamente inferior. Uma pilha de Camadas é composta de Camadas opacas. É o mesmo conceito da estrutura de dados, você não consegue ver o próximo item e não tirar o que está em cima dele.
Nem todas as Camadas são empilhadas porque (1)você pode ter Camadas não-relacionadas na sua alicação que estao em paralelo (e.g. distribuição, persistência, segurança…) e (2) porque as Camadas não precisam obedecer um protocolo de comunicação. Eu posso ter a Camada do topo falando com a de baixo, qual o sentido de falar nisso como uma pilha?
C
cmoscoso
“Pilha de camadas” ou “camadas empilhadas” é redundante. Precisa nomenclatura melhor para o que reside no mesmo nivel.
DDD:
The metaphor of layering is so widely used that it feels intuitive to most
developers. Many good discussions of layering are available in the literature, sometimes in the
format of a pattern (as in Buschmann et al. 1996, pp. 31?51). The essential principle is that any
element of a layer depends only on other elements in the same layer or on elements of the layers
"beneath" it.
pcalcado
Não entendi o que você quis dizer. Para mim pilha de camadas e camadas empilhadas eh a mesma coisa. Como pode-se ver pelo trecho que você citou o Evans discorda do Fowler e do Larman -e eu discordo dele-, qual o ponto?
C
cmoscoso
O ponto é que eu discordo de você…
Utilizando UML e Padrões:
Uma arquitetura multicamadas pode ser caracterizada como composta de camadas e/ou partições… As camadas de uma arquitetura representam os elementos dispostos ao longo da vertical, enquanto que as partições representam uma divisão horizontal de subsistemas, relativamente paralelos, de uma camada…
As camadas, na maioria das arquiteturas multicamadas orientadas a objetos, não estão acopladas no mesmo sentido limitado de um protocolo de redes baseado no Modelo OSI de 7-Camadas… é mais comum que a arquitetura seja uma arquitetura de camadas “relaxada” ou uma arquitetura de camadas “transparente” [Buschmann], na qual os elementos de uma camada se comunicam com diversas outras camadas.
E concordo com Evans, Fowler e Larman!
pcalcado
Eu acho que ou eu não entendi anda que você falou ou você está com problemas para interpretar os textos.
Eric Evans só fala do modelo opaco/empilhado/strict.
Você mesmo já clou o trecho onde Fowler fala que as camadas geralmente são empilhadas/opacas/strict mas que isso não é uma obrigação, então convido a reler o texto e talvez explicar o que você entendeu dele.
Quanto à Larman, o trecho que você mesmo colou te contradiz:
Ou seja: para Larman e Fowler Camadas não recisam ser empilhadas/opacas/strict. Para Evans elas precisam, ams ele não dá soluçòes para os problemas que surgem num modelo empilhado/strict/opaco.
Logo voc6e pode concordar com a dupla ou com o Evans, não com os três.
C
cmoscoso
“…any element of a layer depends only on other elements in the same layer or on elements of the layers beneath it.” - Evans falando de camadas transparentes.
pcalcado:
Você mesmo já clou o trecho onde Fowler fala… …então convido a explicar o que você entendeu dele.
“é mais comum que a arquitetura seja uma arquitetura de camadas “relaxada” ou uma arquitetura de camadas “transparente” [Buschmann], na qual os elementos de uma camada se comunicam com diversas outras camadas.” - Larman falando de camadas transparente.
Portanto, todos falam de camadas como camadas de um bolo, dispostas verticalmente (Larman ainda sugere outro nome para organizacao horizontal) sendo transparente no sentido de permitir que a camada do topo acesse diretamente a primeira ou opaca, quando a camada comunica apenas com a camada imediatamente inferior, sem ser atravessada.
pcalcado
Você está certo quanto ao Evans -eu não vi que o próprio diagrama mostra acamadas transparentes- mas isso e o próprio trecho do Larman que você repetiu pela terceira vez apenas volta para meu ponto inicial:
Como você mesmo provou todos os três autores citados nesta thread concordam com isso. A menos que ocê esteja confundindo empilhamento com disposição eu não entendo como você poderia discordar disso. Vou colar a mensagem onde eu defini empilhamento:
pcalcado:
Acho que o problema então é o conceito de empilhar. Eu usei o termo pela primeira vez em 2005-2006 e sinceramente não sei de onde tirei, acho que do Buschmann mas não estou com o livro em mãos. Todas as outras referências que tenho sequer falam em stacks -exceto pelo Larman que cita network stacks como exemplo de Camadas opacas/empilhadas.
Para mim você empilha Camadas quando faz uma depender da imediatamente inferior. Uma pilha de Camadas é composta de Camadas opacas. É o mesmo conceito da estrutura de dados, você não consegue ver o próximo item e não tirar o que está em cima dele.
Nem todas as Camadas são empilhadas porque (1)você pode ter Camadas não-relacionadas na sua alicação que estao em paralelo (e.g. distribuição, persistência, segurança…) e (2) porque as Camadas não precisam obedecer um protocolo de comunicação. Eu posso ter a Camada do topo falando com a de baixo, qual o sentido de falar nisso como uma pilha?
Voltando à analogia da pilha numa estratéia de camadas empilhadas a camada N só acessa N-1. N-1 acessa N-2 e por aí vai. Numa estratégia transparente você não tem e ssa limitação, N pode acessar qualquer outra Camada diretamente.
C
cmoscoso
Entao concordamos que camadas estao sempre dispostas verticalmente?
pcalcado
Sim e não.
Sim na teoria, não no problem original: negócios depende da persistência e persistência depende do negocio. Em Java eu não sei como resoler este problema sem quebrar Camadas (e sem usar DTOs).
C
cmoscoso
Eu falei da dificuldade aqui:
E a minha solucao:
cmoscoso:
Eu já desencanei do isolamento total faz tempo… eu gosto de ter a camada de insfraestrutura independente. Pra isso eu crio um modulo de infraestrutura de persistencia, e geralmente ele reside no namespace do dominio. É a tal área cinzenta que havia dito.
E DIP é lei, mas estou falando de camadas e camadas…
sergiotaborda
A implementação do repositório pertence à infraestrutura, e não ao domínio. O domínio só conhece a interface; a implementação é injetada de alguma forma na camada de negócios (containers DI, factories, aspectos, etc). Se a implementação do repositório contém X métodos a mais que a abstração, a camada de negócios não sabe nem que esses X métodos existem.
A implementação do repositorio pertence ao dominio e não à infra. A implementação do repositorio pode comunicar-se com a infra se for necessário. A implementação do repositório depende do dominio porque é necessário conhecer a organização do objetos de dominio para responder às pesquisas. Imagine que o seu dominio
usa informações que vê de um WebService. Não ha DAO nem banco. O WebService retorna informações na forma de objetos proprios do WS. E a pesquisa é feita com informações própria do WebService.
O Repositoriotem que traduzir os objetos que chegam do WS para objetos do dominio e as pesquisas do dominio para as pesquisas do WebService. Ele só pode fazer isto se conhecer o dominio.
O repositorio não é construido seguindo o padrão Bridge (ou seja, uma interface + uma implementação) Ele é uma classe. E mais do que isso, ele é um membro de primeira classe na camada de dominio. A sua ideia de que o dominio conhece a interface não se aplica. Nem ha necessidade de injeção uma vez que todas as classes do dominio pertecem juntas. Em muitos casos truques como métodos de visibilidade de pacote são necessários num dominio rico. Isso cai se houve desacoplamento.
Veja bem, todas as classes são do dominio, elas estão acopladas por esse fim : o dominio. Não faz sentido desacopla-las ( seja como DI ou qq outro mecanismo)
tnaires
sergiotaborda:
A implementação do repositorio pertence ao dominio e não à infra. A implementação do repositorio pode comunicar-se com a infra se for necessário. A implementação do repositório depende do dominio porque é necessário conhecer a organização do objetos de dominio para responder às pesquisas. Imagine que o seu dominio
usa informações que vê de um WebService. Não ha DAO nem banco. O WebService retorna informações na forma de objetos proprios do WS. E a pesquisa é feita com informações própria do WebService.
O Repositoriotem que traduzir os objetos que chegam do WS para objetos do dominio e as pesquisas do dominio para as pesquisas do WebService. Ele só pode fazer isto se conhecer o dominio.
O repositorio não é construido seguindo o padrão Bridge (ou seja, uma interface + uma implementação) Ele é uma classe. E mais do que isso, ele é um membro de primeira classe na camada de dominio. A sua ideia de que o dominio conhece a interface não se aplica. Nem ha necessidade de injeção uma vez que todas as classes do dominio pertecem juntas. Em muitos casos truques como métodos de visibilidade de pacote são necessários num dominio rico. Isso cai se houve desacoplamento.
Veja bem, todas as classes são do dominio, elas estão acopladas por esse fim : o dominio. Não faz sentido desacopla-las ( seja como DI ou qq outro mecanismo)
Mas a forma como eu imagino a utilização de um repositório ( foi a forma que eu entendi, claro que posso estar errado ) é a seguinte ( bastante simplificado ):
public interface ClienteRepositorio {
// Métodos para manutenção de objetos de domínio
}
public class ClienteDAO implements ClienteRepositorio {
// Implementação dos métodos de ClienteRepositorio
// Outros métodos implementados pelo DAO
}
Nesse exemplo, todas as classes que usam repositórios ( Services, por exemplo ) possuem declarados em seu corpo atributos do tipo Repositorio, mas os DAOs são injetados de alguma forma no domínio sem que essa camada os conheça.
Assim, você tem ClienteRepositorio pertencendo ao domínio e ClienteDAO pertencendo à infraestrutura.
tnaires
Mais uma coisa Sérgio, no seu artigo sobre repositórios você fala que o repositório depende diretamente da estratégia de mapeamento. Mais uma vez, posso estar errado, mas eu não penso assim. O repositório deve abstrair o domínio de todos esses detalhes, que pertencem à infra-estrutura. Se você quiser manter um mapeamento em memória, deve criar um MemoryDAO, e não um MemoryRepository. Você sugeriu o padrão Strategy pra resolver esse problema, mas eu não consigo conceber um repositório sem implementar Strategy.
sergiotaborda
É o velho problema. Se vc enxerga repository=dao não tenho mais nada a dizer.
Caso contrário, o esquema é o seguinte.
Application — > DAO
Application — > DomainService & Entitys --> Repository --> DAO
O DAO não pode ser acessado pelo dominio. Isto é o que queremos evitar. Se não quer evitar isso, a conversa é futil.
O DAO pode ser acessado directamente da aplicação. Por exemplo: listagens. Um Fastlane enviado pelo DAO é sempre mais eficiente que qq outra coisa no meio. Pesquisas não são logica de negocio. É algo automático, a camada de aplicação (AL) pode cuidar disso sozinha. Contudo, quanto ha um processo qualquer envolvido a AL não pode delegar ao DAO. Ai ela delega a algum Façade/Proxy do dominio. Em algum ponto os serviços precisa conhecer outras entidades existentes. (Por exemplo, quando faz um trasnferencia bancária vc passa duas contas
e um valor, mas vc precisa dos saldos. Os saldos são a soma de da entidade Lançamento. então vc precisa enviar uma pesquisa para o dominio - não para o banco - que lhe retorne todos os lançamentos das duas contas.
E depois soma para ver se pode fazer a transação. Obviamente na prática vc precisa de mecanismo eficazes de fazer isso, mas conceptualmente - do ponto de vista do serviço - é isso que vc está fazendo, e é só isso que interessa)
Vc pode usar o QueryObject (aka Criteria) do seu DAO para fazer a pesquisa, mas isso pula um nivel. Vc não pode user Criteria do DAO no Dominio (layer leak). Então o que vc faz ? Vc isola o dominio com o repositorio.
Vc cria um objeto de qeury proprio do dominio ( sei lá : LancamentosContaQuery pex) e envia ao repositorio.
O repositorio cria o criteria com base no query recebido e enviar ao DAO. Agora, o DAO é maepador de tecnologias e ele NAO É generico. Um dao usando hibernate use criteria para queries, mas um jdbc puro usa sql. etc… Ou seja, o objeto de pesquisa do DAO depende do DAO. A menos que vc use um DomainStore+QueryObject genericos a pesquisa do DAO não e´feita da mesma forma.
Repare que o obtivo principal não é isolar update/insert/delete mas sim o select ( o R de CRUD).
Bom, então vc pode ter um DAO+SQL , um DAO+Criteria, o proprio Hibernate puro + Criteria ( que é um domain store) um EntityManager+SQL , etc… não é só o dao que está em causa é o proprio objeto/forma de pesquisa.
É por isso que vc precisa de várias estratégias. Mas vc só precisa delas se vc pensa em mudar no futuro. Se vc garante que vai usar sempre DAO+SQL (mesmo que o DAO seja implementado via hibernate ou entitymanager etc… ) vc não precisa de estratégias de repositorio.
O strategy é um padrão simples de implementar depois. Ou seja, vc começa com um repositorio que conversa com DAO+SQL. No futuro vc descobre que é melhor DAO+Criteria, vc não apaga o codigo que tem e escreve ouro. Vc passa o codigo do DAO+SQL para uma estratégia e escreve outra para DAO+Criteria. Ha um timing para aplicar o padrão strategy. Eu estou falando dele para mostrar porquê é necessário pensar em termos de strategy.
O repositorio ele mesmo não é uma estratégia. Quantas formas diferentes e simultanear de traduzir o LancamentosContaQuery existem ? Uma só. É a tradução disso para a tecnologia da API de persistencia que muda. quando vc descobrir uma forma mais eficiente de tradução vc apaga a velha. não cria uma estratégia para a velha ( vc nunca a usaria de novo).
Não sei se ficou claro
Domain --------------------------- Repository ---------------------------------------------- DAO
(DomainQuery) ---- > Traduz para linguagem especifica do DAO —> executa e retorna. (é burro)
Se o DAO executa na memoria ou no banco não interessa ao repository. O que interessa é se as queries são feitas do mesmo jeito. uma query em memoria (Filtro) não é passada como no banco (SQL)
P.S: LancamentosContaQuery pode ser encarado como Specification ou QueryObject depende de implementação do repositorio
tnaires
Definitivamente, não. Não sei nem de onde você inferiu isso.
sergiotaborda:
Caso contrário, o esquema é o seguinte.
Application — > DAO
Application — > DomainService & Entitys --> Repository --> DAO
O DAO não pode ser acessado pelo dominio. Isto é o que queremos evitar. Se não quer evitar isso, a conversa é futil.
Não quero necessariamente evitar isso. Eu fico satisfeito se o domínio “pensar” que tá acessando um repositório, apesar de estarmos injetando uma implementação do mesmo - um DAO ou qualquer outra estratégia de persistência.
sergiotaborda:
O DAO pode ser acessado directamente da aplicação. Por exemplo: listagens. Um Fastlane enviado pelo DAO é sempre mais eficiente que qq outra coisa no meio. Pesquisas não são logica de negocio. É algo automático, a camada de aplicação (AL) pode cuidar disso sozinha. Contudo, quanto ha um processo qualquer envolvido a AL não pode delegar ao DAO. Ai ela delega a algum Façade/Proxy do dominio. Em algum ponto os serviços precisa conhecer outras entidades existentes. (Por exemplo, quando faz um trasnferencia bancária vc passa duas contas
e um valor, mas vc precisa dos saldos. Os saldos são a soma de da entidade Lançamento. então vc precisa enviar uma pesquisa para o dominio - não para o banco - que lhe retorne todos os lançamentos das duas contas.
E depois soma para ver se pode fazer a transação. Obviamente na prática vc precisa de mecanismo eficazes de fazer isso, mas conceptualmente - do ponto de vista do serviço - é isso que vc está fazendo, e é só isso que interessa)
Vc pode usar o QueryObject (aka Criteria) do seu DAO para fazer a pesquisa, mas isso pula um nivel. Vc não pode user Criteria do DAO no Dominio (layer leak). Então o que vc faz ? Vc isola o dominio com o repositorio.
Entendo perfeitamente. E o código que postei também é capaz de isolar isso do domínio, uma vez que os objetos Criteria são utilizados somente dentro das implementações ( nesse caso, DAOs ). O que o domínio conhece - através da interface Repositorio - são métodos específicos, como listarClientesInadimplentes(). O DAO que se vire pra retornar esses objetos.
sergiotaborda:
Vc cria um objeto de qeury proprio do dominio ( sei lá : LancamentosContaQuery pex) e envia ao repositorio.
O repositorio cria o criteria com base no query recebido e enviar ao DAO. Agora, o DAO é maepador de tecnologias e ele NAO É generico. Um dao usando hibernate use criteria para queries, mas um jdbc puro usa sql. etc… Ou seja, o objeto de pesquisa do DAO depende do DAO. A menos que vc use um DomainStore+QueryObject genericos a pesquisa do DAO não e´feita da mesma forma.
Isso não é retrabalho? Recriar um mecanismo de busca para o domínio? Além disso, o repositório terá que ter referências a detalhes específicos da tecnologia de persistência empregada. Aqui, por exemplo, é preciso importar para o repositório o pacote que contém a classe Criteria do Hibernate ou JPA.
sergiotaborda:
Repare que o obtivo principal não é isolar update/insert/delete mas sim o select ( o R de CRUD).
Bom, então vc pode ter um DAO+SQL , um DAO+Criteria, o proprio Hibernate puro + Criteria ( que é um domain store) um EntityManager+SQL , etc… não é só o dao que está em causa é o proprio objeto/forma de pesquisa.
É por isso que vc precisa de várias estratégias. Mas vc só precisa delas se vc pensa em mudar no futuro. Se vc garante que vai usar sempre DAO+SQL (mesmo que o DAO seja implementado via hibernate ou entitymanager etc… ) vc não precisa de estratégias de repositorio.
O strategy é um padrão simples de implementar depois. Ou seja, vc começa com um repositorio que conversa com DAO+SQL. No futuro vc descobre que é melhor DAO+Criteria, vc não apaga o codigo que tem e escreve ouro. Vc passa o codigo do DAO+SQL para uma estratégia e escreve outra para DAO+Criteria. Ha um timing para aplicar o padrão strategy. Eu estou falando dele para mostrar porquê é necessário pensar em termos de strategy.
Mas você não vê que está trazendo para a camada de domínio detalhes específicos de infra-estrutura? Um repositório de uma entidade específica deve ser um só, e não ter uma versão para cada método de persistência. Essas estratégias a gente passa pro DAO.
Entendi. Mas isso eu costumo fazer na camada de persistência, e não na de domínio, conforme expliquei anteriormente.
sergiotaborda:
Não sei se ficou claro
Domain --------------------------- Repository ---------------------------------------------- DAO
(DomainQuery) ---- > Traduz para linguagem especifica do DAO —> executa e retorna. (é burro)
Se o DAO executa na memoria ou no banco não interessa ao repository. O que interessa é se as queries são feitas do mesmo jeito. uma query em memoria (Filtro) não é passada como no banco (SQL)
P.S: LancamentosContaQuery pode ser encarado como Specification ou QueryObject depende de implementação do repositorio
A abordagem que eu mencionei anteriormente isola igualmente o domínio desses detalhes. Você teria MemoryDAO, XMLDAO, LapisEPapelDAO… Só seria necessário configurar o mecanismo de injeção para injetar um ou outro.
sergiotaborda
Primeiro que tudo, esqueçamos injeção. DI não tem que ser automático.
O ponto não é esse. Use qualquer objeto e vc pode injetá-lo onde quiser. Não é um problema.
Bom, então esqueça o Repositorio. Vc não precisa dele.
tnaires:
Não é questão se pode. Obviamene pode. A questão é como fazer direito.
Vc pode usar o DAO para isolar. Ok. Mas ai seu DAO não é generico.
Vc gosta de DAO generico ? Eu gosto. Por isso não coloco logicas nele e uso QueryObject.
Se vc não gosta/precisa de um DAO generico, esqueça o Repositorio.
Não ha nehum mal nisso.
O que estou tentando evitar é que vc pense que DAO e Repositorio são a mesma coisa.
Dao é reaproveitável e depende apenas da tecnologia de prevalencia/persistencia.
Repositorio não é reaproveitável e depende do dominio e do DAO.
Vc escreve métodos getClientesAtivos() no DAO em vez de escrever
Query q = Query.newQuery(Cliente.class).add(Restriction.eq("activo", true));
Dao dao
dao.execute(q)
Ok. Nada contra.
Repositorio so se aplica se vc usa a segunda forma.
A primeira forma tem problemas de design (não reutilização do dao em outros dominios, etc…) mas se isso não o desagrada , otimo. Continue usando.
Não é retrabalho se é necessário. E vc não está implementando mecanismo de busca. apenas tradução de queries. O repositorio não tem detalhes da persistencia. Ele usa a interface do DAO ( que por definição isola as tecnologias de persistencia). Criteria do Hibernate não é um detalhes de persistencia, é uma API do hibernate.
Sim, vc tem que importar, e dai ? Esse é o ponto. Vc isola o dominio usando o repositorio como mediador.
Qual é a vantagem ? Polimorfismo.
Se vc tem 10 serviços que controem 1000 Criteria e enviam ao DAO (contruido com hibernate) , na hora que vc quiser reaproveitar esses serviços com XML vc tem que criar outras 1000 criteria e enviar oa DAO XML.
Injetar o DAO não o inibe de ficar dependente da interface do DAO. E se o DAO só aceita Criteria, ou so aceita SQL ou so aceita XPath vc fica agarrado a isso. É isso que não queremos ao usar Repositorio.
Com repositorio vc tem 1000 queries. E ao mudar para XML vc re-escreve 0 queries.
O seu sistema faz mais select ou insert/update/delete ? Na hora de mudar , o que se ferra mais ?
pcalcado
cmoscoso:
cmoscoso:
Eu já desencanei do isolamento total faz tempo… eu gosto de ter a camada de insfraestrutura independente. Pra isso eu crio um modulo de infraestrutura de persistencia, e geralmente ele reside no namespace do dominio. É a tal área cinzenta que havia dito.
E DIP é lei, mas estou falando de camadas e camadas…
Pois é, você acaba não usando uma Camada separada para persistência e sim aglomerando classes com duas responsabilidades distintas (persistência e neócios) na mesma Camada (acho que foi isso que você quis dizer por namespace).
Usar DIP pura e simplesmente faz com que o domínio não dependa da persistência e a persistência dependa do domínio.
O DAO é injetado na Camada de Negócios por algum intermediário imparcial e pronto.
tnaires
No caso, o repositório serviria como fachada para a camada de persistência. Ou seja, só o fato de minha camada de negócios depender de uma abstração da persistência já vale o uso.
Mas agora eu entendi seu ponto. Tudo o que eu estava buscando com a abordagem que ilustrei era exatamente evitar que o repositório dependa do DAO.
Será que não teria uma forma de eu fazer de minha interface Repositorio uma classe concreta usando um DAO genérico ( exatamente o que você disse ), mas sem usar objetos da API de persistência dentro dele?
Não me leve a mal, é que não me entra na cabeça a idéia de um repositório depender de um DAO, ou de qualquer tecnologia de persistência específica. Isso é misturar responsabilidades de domínio com infra-estrutura, queira ou não. Gostaria da opinião de outros membros do grupo sobre essa questão.
Ah, e concordo plenamente com você quando você diz que a abordagem que ilustrei aqui acaba fazendo com que métodos de negócio sejam implementados no DAO, o que é de fato uma desvantagem.
Mas como mostrei, o repositório definiria todos os métodos de negócio necessários relativos à busca de objetos de domínio. O meu DAO usaria Criteria por trás dos panos, sem “estourar” nada pra camada de negócios. Ou seja, nada de Criteria na definição dos métodos. Realmente há desvantagens nisso, como o inevitável estouro de métodos e o fato de reimplementar todos os métodos de consulta ao mudar de implementação de persistência ( como você bem observou ), mas como eu nunca passei por esse tipo de situação, nunca senti falta de trabalhar de uma forma diferente.
Bom, brevemente vou ter a oportunidade de reavaliar tudo isso. Estou prestes a começar um projeto na faculdade e pretendo estudar um pouco mais pra resolver essas “idiossincrasias”.
tnaires
É, Sérgio, definitivamente dou meu braço a torcer.
Acabei de reler o capítulo de repositórios no resumo do DDD publicado pela InfoQ e vi muita coisa que você citou:
Quando eu li o livro do Eric Evans, tive dificuldades em assimilar alguns conceitos e acabei deduzindo coisas. Felizmente comecei a lê-lo novamente e já estou no capítulo 3
Vou tirar da minha cabeça essa neurose de deixar o repositório independente da camada de persistência…
C
cmoscoso
pcalcado:
Pois é, você acaba não usando uma Camada separada para persistência e sim aglomerando classes com duas responsabilidades distintas (persistência e neócios) na mesma Camada (acho que foi isso que você quis dizer por namespace).
Usar DIP pura e simplesmente faz com que o domínio não dependa da persistência e a persistência dependa do domínio.
O DAO é injetado na Camada de Negócios por algum intermediário imparcial e pronto.
Essa é a solucao mais comum, mas não evita a dependencia de baixo pra cima.
O que tenho utilizado é uma camada de persistencia independente sim do dominio, generica a ponto de poder ser utilizada em diferentes projetos.
No dominio/negocio eu tenho os repositorios da forma que você descreveu, usando DIP.
A implementacao trata a persistencia a partir de um nivel mais alto porque delega para a camada de infraestrutura os detalhes e também não contém regras de negócio apesar de depender de objetos de dominio.
Esta atua traduzindo as solicitacoes do cliente da interface para o mecanismo de persistencia. No caso de integracao etnre sistemas eu costumo fazer parecido distribuindo a implementacao num jar separado para fortalecer a ideia de que nao pertence ao dominio apesar de estar dentro dos seus limites. E também porque integracao entre sistemas geralmente é mais comum alterar a anticorruption layer do que a integracao entre o seu sistema e o dominio da persistencia.
sergiotaborda
No caso, o repositório serviria como fachada para a camada de persistência. Ou seja, só o fato de minha camada de negócios depender de uma abstração da persistência já vale o uso.
Podemos entender o repositorio como uma instancia do padrão Façade , mas não com a camada de persistencia.
O repositorio é principalmente um Façade para a camada de busca. Esta camada normalmente tem a ver com a persistencia, mas não é necessáriamente assim ( Lucene).
É necessário esclarecer é que Repository não tem métodos insert/update/delete como o DAO.
Ele só terá esses métodos em casos particulares em que a coleção de objetos é editada pelo proprio dominio.
Se os dados do dominio são alimentados fora dele, o repositorio não tem métodos de alteração.
Acontece que normalmente o dominio faz algum tipo de alteração e é então que é mais logico usar o repositorio como centralizador dessa necessidade. Mas isso é dar ao repositorio responsabilidades a mais. A base dele não é essa. Não é para isso que ele é criado. Não é para isso que ele existe. Mas uma vez que existe, ele pode também ter essas responsabilidade. ( por isso que nem todas as entidades têm um repositorio)
O DAO não é um objeto sozinho quando fazemos pesquisas. Eles usa alguma linguagem para essa pesquisa.
Estamos partindo do principio que o DAO tem essa linguagem. Se não tem, ele tem métodos especiais do tipo getClientesAtivos() o que o torna não reaproveitável e uma violação do principio de SoC. (um DTO-sabe-tudo)
Portanto, durante a pesquisa o DAO tem um objeto associado. Esse objeto (SQL=String, Criteria, queryObject, etc…) é que é o problema. Não queremos depender desse objeto. Se o DAO é reaproveitável queremos aproveitá-lo em outros sistemas. E ao mesmo tempo queremos ser livres de mudar nosso DAO por um melhor (por exemplo, um que usa melhores implementações ou avançados do JDBC ).
Mas se o DAO depende de uma linguagem de pesquisa e não isolamos essa linguagem, não podemos mudar de DAO.
Na prática, vc tem um DAO para banco de dados e usa SQL para os queries.Um dia vc quer lançar um demo readonly do seu sistema. Ai vc pensa em usar XML porque o overhead do banco seria inutil. Mas ai como vc vai transformar as queries SQL em XPath ? Colocar SQL como linguagem de procura de XML é estranho. Ai vc vai disistir do XML e forçar o uso de um banco em memoria (quando vc sabe que não quer isso). Vc se amarrou a si próprio (lock down) ao uso de SQL. O repositorio evita isso.
E relembro que não se troca de repositorio. Ele é sempre o mesmo. O repositorio é que troca de estratégia.
O repositorio não é definido por uma interface. Ele não é um contrato, é um “braço” do sistema.
Não. Imagine que eu crio um DomainStore muito bom , que usa QueryObject. Estas classes não dependem de dominio e não dependem de API de persistencia. Vc pensa: “legal, agora posso ligar o dominio com este storage porque não dependo do DAO. Os query objets não vão mudar porque o DomaisStore vai isolar isso de mim e traduzir o query para a tecnologia subjacente ( Xpath, SQL, etc…)”
Neste cenário o uso de Repository parece inutil. Só que uma outra empresa desenvolveu um DomainStore que é 100 vezes mais rápido que este. As queries são escritas de forma mais simples e é compativel com mais tecnologias de persistencia (bancos OO , por exemplo). Vc quer mudar para este novo DomainStore muito bom.
Mas vc não pode, porque teria que reescrever os queries com a nova API.
Se estiver usando repository, vc cria uma nova estratégia e pronto. Quando a empesa nova começar a cobrar pelo uso e vc não quiser pagar, vc volta à estratégia antiga.
Este exemplo é muito simples de entender. Todo o mundo usava JDBC com SQL. Todas as queries eram escritas directamente no codigo ( mesmo que dentro do DAO-sabe-tudo). Um dia veio o hibernate. Vc acha que alguem vai algum dia mudar aqueles SQL para Criterias do Hibernate ? Claro que não, porque isso custa dinheiro.
Claro que é sempre possivel refactorar um codigo e introduzir um repositorio onde nenhum existia antes. Afinal a pessoa/equipe aprendeu com seus erros. Mas isso tb é caro. A opção mais barata é usar o repositorio de um principio.
Agora, o repositorio pode receber objetos QueryObject e traduzir para o DAO. Mas ele também pode ter métodos do tipo getCLientsAtivos() e implementar directamente para o DAO. Do ponto de vista OO é a mesma coisa porque invocar find(QueryObject) ou getClientsAtivos() é a mesma coisa. Vc está enviando uma mensagem ao repositorio e ele responde. A escolha é sua.
Repare que se o repositorio usar queryObject esse query será especifico do dominio , logo, não ha perigo disso ter que mudar depois.
tnaires
OK, tudo entendido. Só ficou mais uma dúvida:
sergiotaborda:
Podemos entender o repositorio como uma instancia do padrão Façade , mas não com a camada de persistencia.
O repositorio é principalmente um Façade para a camada de busca. Esta camada normalmente tem a ver com a persistencia, mas não é necessáriamente assim ( Lucene).
É necessário esclarecer é que Repository não tem métodos insert/update/delete como o DAO.
Ele só terá esses métodos em casos particulares em que a coleção de objetos é editada pelo proprio dominio.
Se os dados do dominio são alimentados fora dele, o repositorio não tem métodos de alteração.
Acontece que normalmente o dominio faz algum tipo de alteração e é então que é mais logico usar o repositorio como centralizador dessa necessidade. Mas isso é dar ao repositorio responsabilidades a mais. A base dele não é essa. Não é para isso que ele é criado. Não é para isso que ele existe. Mas uma vez que existe, ele pode também ter essas responsabilidade. ( por isso que nem todas as entidades têm um repositorio)
Ué, mas se o repositório não deveria fazer isso, quem deveria então? Services?
Alessandro_Lazarotti
Concordo com essa afirmação do Sérgio e discordo da afirmação do Shoes quanto a repositorios não conter regras.
Exemplos comuns e úteis para o negócio:
Alguns objetos do domínio podem precisar de algo como histórico de transações - normalmente objetos inserido em algum flow de processos. Esse histórico não é simplesmente um controle de rastreabilidade, pode ser que o usuário utilize o histórico para copiar informações do processo para um novo processo, isso é negócio. Ao utilizar o repositório para armazenar estes dados, seria prudente que ele armazenasse também uma cópia deste para um outro repositório, o de histórico. Essa atividade seria comum para todas as atividades de armazenamento para este tipo específico de repositório, deixa-la em um Service seria perigoso, lembrando de sempre ter que invocar o repositorio de historicos depois de algum adicionar, atualizar ou remover no repositório do objeto de domínio.
Existem dados que devem ser criados quando se efetua, por exemplo, operações de adição no repositório. Toda vez que um determinado objeto for adicionado, deve ser atribuído a ele uma identificação serial com base em uma estratégia pré determinada. Note que isso não deve ser feito quando o objeto é criado (o que pode ser comum na maioria dos casos), mas somente quando ele for persistido… isso pode vir a ser um requisito de negócio.
Ou seja, não existe uma posição absoluta em dizer que jamais se deve usar isso em um repositório. Tanto para o time quanto para o cliente, pode vir bem certeiro atribuir certas regras para a área de atuação no armazenamento dos dados. Utilizar sempre Services para isso, pode ser um desperdício tremendo …
sergiotaborda
tnaires:
OK, tudo entendido. Só ficou mais uma dúvida:
sergiotaborda:
Podemos entender o repositorio como uma instancia do padrão Façade , mas não com a camada de persistencia.
O repositorio é principalmente um Façade para a camada de busca. Esta camada normalmente tem a ver com a persistencia, mas não é necessáriamente assim ( Lucene).
É necessário esclarecer é que Repository não tem métodos insert/update/delete como o DAO.
Ele só terá esses métodos em casos particulares em que a coleção de objetos é editada pelo proprio dominio.
Se os dados do dominio são alimentados fora dele, o repositorio não tem métodos de alteração.
Acontece que normalmente o dominio faz algum tipo de alteração e é então que é mais logico usar o repositorio como centralizador dessa necessidade. Mas isso é dar ao repositorio responsabilidades a mais. A base dele não é essa. Não é para isso que ele é criado. Não é para isso que ele existe. Mas uma vez que existe, ele pode também ter essas responsabilidade. ( por isso que nem todas as entidades têm um repositorio)
Ué, mas se o repositório não deveria fazer isso, quem deveria então? Services?
Se o seu dominio escreve/altera a coleção que ele próprio consulta, então o repositorio tem metodos de alteração.
Para os dados que o dominio não manipula a aplicação pode se encarregar disso usando o DAO diretamente.
Pegando um pouco no que o Lezinho falou, existem regras que devem ser implementadas quando é algo é guardado. Esse evento indica que a partir daquele momento aquela instancia de uma entidade pertence ao dominio. Isso pode provocar a criação de outras instancias de outras entidades, etc…
Mas isso tb pode acontecer quando a aplicação usa o DAO automaticamente. Ai teriamos que forçar a aplicação a usar o Repositorio para forçar as regras. O problema é que input do repositorio está preparado para comunicar com o dominio e a apicação teria que usar elementos do dominio para invocar o repositorio nessas ocasiões. (violando assim o SoC). Poderiam criar um Serviço que a aplicação chame. O Serviço esta para a camada de aplicação como o repositorio para a de persistencia, portanto deveria funcionar. O problema é criar um serviço de dominio que faz coisas de infra.
Mas , supondo que responder a save não é um problema de infra e sim de dominio, é o hook que fica meio complicado de escolher. Ambos (aplicação e dominio) irão provocar save de entidades.
algumas aproximações a considerar:
Se persistir provoca acontecimentos no dominio, a persistencia em si ( não o local ou a tecnologia ) fazem parte do dominio. Neste caso o façade pode ser criado como a única interface para ler e escrever dados.
Um mecanismo de chain of responsability semelhante aos filtros de sevlet (conhecido como o padrão Interceptor) pode ser usado para injetar “triggers”. O objeto de persistencia irá chamar os interceptores em ordem e so no fim persistir realmente. Desta forma os dados podem ser manipualdos e novos dados podem ser adicionados à persistencia. è como se novos dados se adicionassem ao dado original no seu caminho para a persistencia.
Um mecanismo de listeners e eventos pode ser criado para o objeto de persistencia. Objetos interessados podem responser aos eventos. Os eventos podem ser consumidos por vários objetos.
C
cmoscoso
Se é um requisito de negócio deve ser representado no modelo de dominio, repositorios não expressam o modelo de dominio. Qual o benefício em esconder algo que é importante pro negócio em um mecanismo puramente de acesso?
Repositorios e factories não são como entities, value objects e services e não é à toa que eles possuem um capítulo a parte no livro.
A regra geral é simples, se for regra de negócio deve ser expresso no modelo de dominio.
Alessandro_Lazarotti
Meu repositório atuando no domínio, que é sua camada, pode inclusive pertencer a modelagem natural, tudo depende da situação.
Eu tenho uma conversa fluente como especialista de negócio dizendo que ao armazenar determinado dado, um determinado evento acontece. Inclusive desenhando um repositorio de dados e ligando um conjunto de dados (de uma entidade) a ela é totalmente entendível nas reunioes.
Alessandro_Lazarotti
Não existe regra simples, existe situações simples e complexas. Qual estratégia tomar, depende da contextualização do meio.
pcalcado
É o mesmo exemplo que tem no livro só que com generics no lugar de casts.
Perguntas:
como você faz para ter uma consulta personalizada parametrizável? Todas as vendas entre 1/2 e 2/3 de 98 feitas por senhoras com mais de 90 anos.
Este tipo de coisa não é geralmente possível com um Data Mapper genérico.
Eu costumo resolver de três formas:
1 - Usando QueryObjects
2 - Usando metadados (named queries e etc) nos objetos de negócio
3 Criar um framework de consultas genérico (talvez backed por Criteria API), montar as consultas com abstrações de negócio e mapear para consultas reais.
A opção 1 não segue sua idéia, é a mesma coisa que falei anteriormente.
A opção (2), além de não se alicar em sistemas sem um ORM poderoso, inclui metadados de persistência nos objetos de negócio e apesar do valor prático ser interessante não deixa de ser quebra de Camadas.
A opção (3) provavelmente é a melhor para mantêr, mas depende da infra-estrutura disponível -EJB ainda não tem criteria, creio.
Eu prefiro a opção (1) em geral porque eu prefiro inverter a dependência de Camadas do que depender tanto da inra-estrutura, mas a verdade é que os meanismos de ORM modernos tiraram boa parte da funcionalidade do DAO.
pcalcado
Eu diria que se seu teu domínio tem algo que dispensa um repositório provavelmente ele tem outro nome. Repository é um padrão criado para rpeencher um buraco na maioria dos domínios, que dificilmente possuem um conceito bem estruturado sobre para onde vão e de onde vêm as instâncias.
Eu não falei que Repositório não contêm regras, o que eu falei é que diicilmente o domínio vai exigir regras no repositório -simplesmente porque Repositório é uma abstração artifical.
Isso é regra de persistência, não de negócio. Para o negócio uma conta é o resultado das operações, o fato de que trazer todas as operações para a memória é custoso e por isso elas não estão disponíveis de graça (diferente de dados mais simples como nome do titular da conta) Não é regra de negócio.
Esse é um exemplo razoável, mas eu faria isso num Service que processaria qualquer regra necessária e passaria para o Repositório para persistência.
Alessandro_Lazarotti
O meu dominío não tem algo que dispensa o repositório, na realidade o pensamento é o inverso, meu domínio conhece o repositório (o que é natural para um Data Model). Note que conhecer o repositório não fere camada alguma (não me refiro em momento algum a abstração de persistência) e dá mais sentido ao negócio.
Não é infra, nem o especialista e nem o time esta dando detalhes como o objeto será persistido, mas todos estão tratando que invariavelmente uma ação deve ocorrer no momento que o sistema preservar o estado de determinado objeto.
De fato, quem esta abstraindo a infra é uma Strategy membro do repositório e a QueryObject, e não a implementação do repositório em sí. Por isso, um conceito estruturado de onde vão e de onde vem as instancias, continuam abstraídos.
Somado a isso, como tentei exemplificar, em determinados casos um próprio armazenamento de dados pode ser de interesse ao negócio e transparente para o Domain Especialist. Não foi apenas uma vez que eu ouvi casos como : SEMPRE SEMPRE SEMPRE que guardar esse conjunto de dados, a tarefa “X” deve ser executada. Um Service realizando tal requisito poderia servir, mas atribuir a ele um “adicionar(objetoDeNegocio)”, apenas para satisfazer a consciência de alguns desenvolvedores, parece mais distante do cliente e perigoso no decorrer do desenvolvimento da aplicação. Se um desenvolvedor resolve comumente adicionar o objeto diretamente pelo repositorio (o que não seria difícil de acontecer e gramaticamente faz sentido), a aplicação não vai se comportar conforme esperado. Isso poderia ser evitado sem grande esforço, sem fugir do domínio e sem sair do universo proposto pelos Stakeholders.
Reforçando, não são simples regras de persistências, são relevantes para o domínio e este as conhecem. Mas concordo que estas são algumas situações, que talvez não se aplique a qualquer projeto, mas que não raramente acontecem.
C
cmoscoso
Qual livro? E se não for pedir muito, a página…
pcalcado:
Perguntas:
como você faz para ter uma consulta personalizada parametrizável? Todas as vendas entre 1/2 e 2/3 de 98 feitas por senhoras com mais de 90 anos.
Este tipo de coisa não é geralmente possível com um Data Mapper genérico.
Eu costumo resolver de três formas:
1 - Usando QueryObjects
2 - Usando metadados (named queries e etc) nos objetos de negócio
3 Criar um framework de consultas genérico (talvez backed por Criteria API), montar as consultas com abstrações de negócio e mapear para consultas reais.
A opção 1 não segue sua idéia, é a mesma coisa que falei anteriormente.
A opção (2), além de não se alicar em sistemas sem um ORM poderoso, inclui metadados de persistência nos objetos de negócio e apesar do valor prático ser interessante não deixa de ser quebra de Camadas.
A opção (3) provavelmente é a melhor para mantêr, mas depende da infra-estrutura disponível -EJB ainda não tem criteria, creio.
Eu prefiro a opção (1) em geral porque eu prefiro inverter a dependência de Camadas do que depender tanto da inra-estrutura, mas a verdade é que os meanismos de ORM modernos tiraram boa parte da funcionalidade do DAO.
Eu uso specifications. Há limites no nivel de personalizacao obtido mas tem atendido minhas necessidades.
C
cmoscoso
Isso eu acho muito improvável!
Lezinho:
Um Service realizando tal requisito poderia servir, mas atribuir a ele um “adicionar(objetoDeNegocio)”… …parece mais distante do cliente e perigoso no decorrer do desenvolvimento da aplicação. Se um desenvolvedor resolve comumente adicionar o objeto diretamente pelo repositorio (o que não seria difícil de acontecer e gramaticamente faz sentido)
Você tocou na questão chave, a nomenclatura!
Você nao vai criar um metodo no service dessa maneira porque ele nao expressa na UBIQUITOUS LANGUAGE o tal evento de interesse do negocio.
Alessandro_Lazarotti
Bem que eu tbm gostaria de achar improvável, mas não fui eu que defini o caso de uso, foi o usuário, e os termos foram os dele e não os meus.
… eu não tenho outro nome para uma regra que o usuário definiu para persistir os dados. A segunda ação esta definida tbm, inclusive poderia esta em uma real entidade do negócio, mas quem a executa é o repositorio no momento da inserção. E olha, se um argumento, que não seja simplesmente “você nao pode fazer isso, simplesmente pq não pode”, fizer sentido… eu não exitaria de acatá-lo.
C
cmoscoso
Eu sei como é esse tipo de gente…
pcalcado
DDD, Não sei a página porque estou quotando do Safari:
[quot]Typically teams add a framework to the infrastructure layer to support the implementation of REPOSITORIES. In addition to the collaboration with the lower level infrastructure components, the REPOSITORY superclass might implement some basic queries, especially when a flexible query is being implemented. Unfortunately, with a type system such as Java’s, this approach would force you to type returned objects as “Object,” leaving the client to cast them to the REPOSITORY’S contained type. But of course, this will have to be done with queries that return collections anyway in Java.
[/quote]
cmoscoso:
Eu uso specifications. Há limites no nivel de personalizacao obtido mas tem atendido minhas necessidades.
A única maneira que eu vejo de usar specifications no meu exemplo (e é o que uso) é no caso (1) com a dupla QuryObject/Specification, que é uma aplicação do tipo (1). Se você fizer isso ainda cria uma dependencia entre os query objects e o domínio, caindo no mesmo problema do DAO vs Repository, então acho que não deve ser isso.
Como você faz exatamente? Retorna todos os objetos e aplica uma Specicication como se fosse um Visitor?
pcalcado
Lezinho:
O meu dominío não tem algo que dispensa o repositório, na realidade o pensamento é o inverso, meu domínio conhece o repositório (o que é natural para um Data Model). Note que conhecer o repositório não fere camada alguma (não me refiro em momento algum a abstração de persistência) e dá mais sentido ao negócio.
Não é infra, nem o especialista e nem o time esta dando detalhes como o objeto será persistido, mas todos estão tratando que invariavelmente uma ação deve ocorrer no momento que o sistema preservar o estado de determinado objeto.
[…]
Somado a isso, como tentei exemplificar, em determinados casos um próprio armazenamento de dados pode ser de interesse ao negócio e transparente para o Domain Especialist. Não foi apenas uma vez que eu ouvi casos como : SEMPRE SEMPRE SEMPRE que guardar esse conjunto de dados, a tarefa “X” deve ser executada. Um Service realizando tal requisito poderia servir, mas atribuir a ele um “adicionar(objetoDeNegocio)”, apenas para satisfazer a consciência de alguns desenvolvedores, parece mais distante do cliente e perigoso no decorrer do desenvolvimento da aplicação. Se um desenvolvedor resolve comumente adicionar o objeto diretamente pelo repositorio (o que não seria difícil de acontecer e gramaticamente faz sentido), a aplicação não vai se comportar conforme esperado. Isso poderia ser evitado sem grande esforço, sem fugir do domínio e sem sair do universo proposto pelos Stakeholders.
Eu acho que você está confundindo persistência com worflow /troca de estados.
Para Orientação a Objetos em si não existe persistência, o fato que um objeto deve ser persistido em um SGBD ou o que for é uma limitação. Um objeto não precisa ser pasado para ser salvo pelo repositório para estar ‘vivo’. Na verdade, o Repositório idealmente apenas serve para pesquisar, não para salvar objetos. O fato de que o objeto tem que ser salvo em algum onto explícito -se você não usar uma Unit of Work da vida- é uma deformação do modelo.
Se seu usuário mencionou ‘salvar’ provavelmente ele está com o vocabulário poluído com termos técnicos, porque ele está acostumado a fazer isso (da mesma forma um editor de texto pede que você salve o documento quando precisar porque ele não pode mantêr todas as versões e salvar a cada alteração) , mas no final das contas isso vira uma regra de negócio e deve ser implementado como qualquer outra regra. O que ele quer dizer é que quando o bojeto atingir o estado ‘salvo’ tal coisa deve acontecer, não quando o objeto for persistido (i.e. salvo em uma tabela relacional).
No seu exemlo acima eu considero SALVO como o estado que um objeto atinge. Pode ser que seja necessário um Service para "executar a tarefa X"mas acho que na maioria dos casos ela pode ficar como Observer do objeto em questão.
Alessandro_Lazarotti
Lezinho:
(…)não me refiro em momento algum a abstração de persistência(…)
… como você pode notar Shoes, eu nãO estou me referindo a persistência, nem especifiquei que o usuário se referiu a ela. A história do usuário implica que toda vez (se e somente se) determinada entidade estiver “pronta” (tipada em “guardar determinados dados”) execute a tarefa X.
Sim, isto pode ser classficado como estado do objeto, mas não muda o problema. Como também mencionei, o fato do user case exigir esta dependecia durante a “ação de manter” o estado da entidade, atribuir isso a um Service pode vir dar problemas, como escrevi no post anterior:
… ja o Observer pode ser mais interessante. Contudo, registrar o listener no Repository pode ser tão intrusivo quanto realizar nele a chamada para execução da tarefa “X”, como descrevi:
Quem mantém o estado é o repository, não vejo como garantir o comportamento requerido sem que ele invoque alguma regra do domínio para este caso, mesmo caracterizando ele como um Event do Observer. Talvez eu não tenha enxergado ainda uma implementação do Observer que possa ajudar neste caso… você pode dar uma dica?
PS: Insisto neste assunto pq já implementei isso em Service e realmente não fiquei satisfeito, justamente pelos problemas que explanei.
pcalcado
Lezinho:
Lezinho:
(…)não me refiro em momento algum a abstração de persistência(…)
… como você pode notar Shoes, eu nãO estou me referindo a persistência, nem especifiquei que o usuário se referiu a ela. A história do usuário implica que toda vez (se e somente se) determinada entidade estiver “pronta” (tipada em “guardar determinados dados”) execute a tarefa X.
Exatamente, mas como eu falei no meu ost o fato de que o Repositório possui um método save() é um acidente. Quem troca o estado do objeto é ele mesmo, não uma entidade externa, então quem deve realizar uma lógica em decorrência desta troca deve ser avisado sobre o evento elo objeto.
Talvez eu não tenha sido claro: não, ele não tem adicionar(). Adicionar, salvar ou o que for só existem poque você precisa amntêr estado artificialmente, para o modelo de objetos todo objeto criado já está ‘adicionado’. O ‘adicionar’ do seu exemplo é meramente uma troca de estado.
Novamente: o Repository -pode ate ser, mas nao eh na minha ideia- não e o observador, o observador vai ser outro objeto que pode ser uma entity ou service.
Como falei, quem mantem o estado não é o Repository, é o objeto. Esse é o rincípio básico de Orientação a Objetos, objetos gerenciam seu estado e sofrem mudanças de acordo com estímulos externos. Quando o objeto muda d estado ele pode avisar outros objetos, sema entities ou services ou o que for, e esses tomam alguma atitude. No final das contas seu mecanismo de persistência tira uma foto do estado final e guarda no banco de dados, isso pode ser tão invasivo como repositorio.adicionar()/salvar() ou tão transparente quanto usar EJB3/Hibernate.
C
cmoscoso
pcalcado:
A única maneira que eu vejo de usar specifications no meu exemplo (e é o que uso) é no caso (1) com a dupla QuryObject/Specification, que é uma aplicação do tipo (1). Se você fizer isso ainda cria uma dependencia entre os query objects e o domínio, caindo no mesmo problema do DAO vs Repository, então acho que não deve ser isso.
Como você faz exatamente? Retorna todos os objetos e aplica uma Specicication como se fosse um Visitor?
Seguinte, o que as 3 solucoes que você apresentou tem em comum é obter uma SQL para executar a tal consulta. Atualmente na minha camada de infraestrutura (Repository<T>) eu tenho essa possibilidade de executar uma SQL, mas a sua construcao ocorre onde é a implementacao do repositorio.
Diga-me se nao consegui ser claro…
pcalcado
Não entendi. Dúvidas:
1 - Aguém tem que fazer ResultSet <=> Domínio e esse alguém precisa conhecer o domínio (nem que seja por configuração). Onde você faz essa transformação?
2 - Alguém precisa gerar o SQL(ou HQL, ou EJBQL, o que for…), onde ele é gerado?
Pelo que entendi o SQL é gerado no repositório, mas acho que não é isso que você disse porque aí teríamos um objeto da camada de negócios sabendo sobre como gerar SQL. Uma forma de evitar isso é QueryObjects implementando Specifications, é isso que você faz?
Alessandro_Lazarotti
Bom, o repositório como sendo, abstratamente, uma coleção de objetos em memória, adicionar ou remover elementos nesta coleção não me parece ser algo tão “acidental” ou distante do foco do negócio.
Usuários fazem buscas interessantes e relevantes para o domínio, em algo que eles acreditam armazenar informações (um repositório de dados). Introduzir mais dados ou remover, desta mesma coleção de informações não é algo que o usuário ignore, por vício de tratar com sistemas automatizados ou não.
Perder esse conhecimento e interação com os usuários não sei até que ponto é interessante.
pcalcado
O unico motivo para o reposit’orio ser introduzido como uma colecao em memoria eh porque essa eh a maneira mais facil de fazer um desenvolvedor pensar sobre ele. Essa 'e uma abstra’c~ao para o desenvolvedor, nao para o negocio.
Idealmente o repositorio seria capaz de buscar todos os objetos, mesmo os que ainda nao foram persistidos.
Se voce de fato tem um Repositorio de dados como um conceito de negocio, e nao apenas como uma abstracao acidental, ele provavelmente tem um nome como eu disse anteriormente. ContaCOrrente eh um repositorio consolidavel de transacoes bancarias por exemplo.
Eu acho que voce esta deixando vazar conhecimento de implementacao e limitacoes na modelagem para o negocio. Isso eh normal e se funciona para voce tudo bem, desde que nao se torne patologico. Isso eh apenas mais uma manifestacao da Law of Leaky Abvstractions
Alessandro_Lazarotti
Ok amigo, vamos ao seguinte:
O cliente me pediu que implementasse aquela tarefa “X” daquela forma: “Quando eu clicar no botão SALVAR, execute a tarefa X e salve os dados”.
Ele não sabe o que é abstração dos dados de uma forma de persistência. Mas eu e a equipe sabemos que a tarefa X é totalmente pertinente a entidade a ser persistida, portanto, ela é um método daquela entidade.
… é da linguagem dele e faz parte das interações com o sistema clicar no botao “SALVAR”. Ele pode ter inclusive esta operação sobre esta entidade, em mais de um ponto do sistema.
Inclusive, antes dele pedir que se executasse a “tarefa X”, os eventos sobre os botões estavam assim nas páginas:
Com a alteração que o usuário pediu, eu não mexeria nas páginas (já que se tornou um requisito realizar a tarefa antes de persistir os dados), mas faria:
Isso resolve o problema para todas as chamadas que eu tinha para o evento de “Salvar” sobre essa entidade, disparado pelo usuário. E ao meu ver não feriu camadas alguma (tudo continua no domínio). É claro que essa não é uma prática para todas as situações, inclusive não é tão comum, mas eu puxei essa discussão pelo seu post seu com o Moscoso de ‘nunca’ atribuir uma regra no repositório. Na prática, isso pode em determinados casos ajudar e muito…
Pelo lado técnico da coisa, minha entidade acaba sendo o observável ‘pelo Repositório’ (ok, sei q vc disse que para vc não seria assim). Já que o objeto gerencia seu estado, o repositório é informado (pela UI ou facade) que o estado do objeto é ‘pronto’ e dispara a ação, assim como o usuário definiu.
Isso não é regra, e meus repositórios não estao cheios disso, mas já usei, sem dor na conciência.
Exemplificando Shoes (com pseudo-códigos ?) , como você resolveria de forma eficiente isso?
pcalcado
Você está novamente falando sobre coisas que eu não falei, peço para que se atenha a este detalhe. Eu não falei em Camadas (minha discussão com o Moscoso é sobre algo completamente diferente do que voê está falando) e nem que Repositório nunca tem regra de negócio. É a segunda vez que eu repito isso e peço para que você se lembre disso.
Lezinho:
Ok amigo, vamos ao seguinte:
O cliente me pediu que implementasse aquela tarefa “X” daquela forma: “Quando eu clicar no botão SALVAR, execute a tarefa X e salve os dados”.
Ele não sabe o que é abstração dos dados de uma forma de persistência. Mas eu e a equipe sabemos que a tarefa X é totalmente pertinente a entidade a ser persistida, portanto, ela é um método daquela entidade.
… é da linguagem dele e faz parte das interações com o sistema clicar no botao “SALVAR”. Ele pode ter inclusive esta operação sobre esta entidade, em mais de um ponto do sistema.
Inclusive, antes dele pedir que se executasse a “tarefa X”, os eventos sobre os botões estavam assim nas páginas:
Com a alteração que o usuário pediu, eu não mexeria nas páginas (já que se tornou um requisito realizar a tarefa antes de persistir os dados):
Eu não sei quão ‘pseudo’ é seu código mas vejo um problema aí: você não está usando uma Camada de Aplicação. Se você usasse uma Camada de Aplicação não precisaria se preocupar tanto com “eu não mexeria nas páginas”.
Resolver resolve, assim como não usar conceitos de DDD ou mesmo não usar orientação a objetos também resolve. Por isso que falei antes: se funciona para você ótimo. O ponto é que o repositório não é o lugar para esta regra, imho, simplesmente porque o fato que um objeto vai ser adicionado é simplesmente uma limitação técnica, não um conceito de negócio. Ainda que fosse implementar algo procedural desta forma eu optaria por um Service do o repositório.
Desculpe mas isso não tem nada de observer. Primeiro porque não há mudança de estado, emv ez de o estadoe star no objeto como se espera em um programa OO ele está sendo manipulado por outro objeto, e por isso meu comentário sobre código procedural acima.
Lezinho:
Exemplificando Shoes (com pseudo-códigos ?) , como você resolveria de forma eficiente isso?
Vou omitir a interface porque ela é irrelevante nesta discussão, assuma que o código abaixo é chamado pela Camada de Aplicação.
Supondo que quando um pedido eh processado (“salvo”) eu preciso gerar e persistir um outro objeto chamado NotaFiscal.
Modelo mais procedural para parecer mais com a estratégia que você adotou:
Como falei a abordagem acima segue o mesmo princípio procedural mas remove a lógica do Repositório. Já é ruim o Repositório ter que adicionar objetos, adicionar lógica de negócios a iso é misturar uma necessidade técncia com uma necessidade do modelo.
Mesmo adotando este estilo, como falei antes, vale a pena investigar uma forma mais inteligente de fazer o Workflow, a mudança de estado pode merecer ser modelada através de um Service mais coerente e coeso.
Vamos tentar fazer algo mais OO:
classPedido{publicvoidterminar(){this.status=Status.PROCESSADO;for(Observadorobservador:observadores)observador.notificar(this);}}classWorkflowPedido{PedidocriarNovoPedido(){//isso estaria melhor numa factoryPedidop=newPedido();p.adicionaObservador(emissorNota);}voidterminarProcessamento(Pedidop){p.terminar();//essa chamada faz parte da complexidade acidental e pode ser omitida dependendo da infra-estruturarepositorioPedidos.adiciona(p);}}classEmissorNotas{publicvoidnotificar(pedidop){if(p.status()==Status.PROCESSADO)gerarNotaFiscal(p);}voidgerarNotaFiscalPara(Pedidop){NotaFiscalnf=newNotaFiscal(p);nf.algumaCoisa();//essa chamada faz parte da complexidade acidental e pode ser omitida dependendo da infra-estruturarepositorioNotaFiscal.adiciona(nf);}}
Dessa forma quem controla a mudança de estados e a notificação dos interessados é o objeto. O Service sequer precisa sabe 9se você extrair numa fábrica, como sugerido) quem observa o objeto e você pode adicionar novos comportamentos facilmente.
Resumindo:
Eu não falei que Repositório não tem regra, não sei de onde você tirou isso, falei que dificilmente vai ter
Seu exemplo sente falta de uma Camada de Aplicação, acredito que isso faz com que a regra estar no Repositório seja algo natural para você
“Adicionar ao Repositório” é um requisito técnico derivado de uma limitação, não misturar regra de negócio com limitação écnica é uma boa idéia
Existem bilhões de maneiras de fazer isso sem colocar regras no repositório, maneiras mais ou menos OO
Se funciona para você e se você acredita que consegue software de boa qualidade fazendo isso ótimo. Arquitetura (e design) é sobre pessoas, não sobre religião
Emerson_Macedo
Estou observando a discussão desde o inicio, e tem algo sobre o problema do Alessandro que eu gostaria de comentar:
A facilidade que o Seam trás de acessar os objetos direto, fugindo um pouco do modelo de trabalho anterior do JSF acaba induzindo algumas pessoas a acessar repositório dessa forma direto da JSP. Existem muitas pessoas que estão fazendo isso, porém não acho isso uma boa idéia, justamente por causa desse problema que foi descrito aqui. O cliente precisa de mais uma coisa ai seu repositório vira camada de aplicação, service, ou sei la o que, e ai começa a salada. Mas em fim, tudo isso é a minha opinião.
Alessandro_Lazarotti
1)Eu não afirmei nada sobre alguma menção sua a “camadas”, me referi a repositórios, mais precisamente sobre o conteúdo acima. Você não mencionou ‘nunca usar regras’, mas é o que da-se por entender com a afirmação (a não ser que fosse levado em conta algo ‘sobrenatural’). Caso o entendimento não for esse, minha desculpas …
2)A necessidade de uma camada de aplicação é questionável. De início, a única coisa a ser feita era apenas guardar o estado do objeto em um meio persistente (sim, por limitação da tecnologia). Poderia criar uma façade para a aplicação, a fim dela chamar o repositorio, mas em uma relação 1 para 1, não vejo ganho. Com a mundança no requisito, eu deveria certificar que todos os pontos do sistema que fazem chamada ao meio persistente para aquele objeto tbm fossem invocados pela mesma façade (para valer do requisito), o que pode não ser verdade.
3)O Segundo exemplo seu é bem modelado. Não tenho nada o que criticar a respeito. Contudo note que o objeto com o comportamento ‘terminar’ ja estaria previamente modelado, e assim adicionar observadores a ele de fato não exige muita complexidade (o que é ótimo). Mas em uma situação que onde a ação da aplicação era somente preservar o estado de um objeto, refatorar a modelagem para este código pode não ser tão simples e a contextualização do negócio pode não ser cabível… por exemplo se seu objeto de domínio, diferente da classe Pedido que você modelou, não possuisse algo como ‘terminar’.
4)Quanto ao código ser mais ou menos procedural, veja que a única coisa que o repositório fez em meu exemplo é uma delegação, ele não alterou o estado de ninguém, se tarefaX fazer isso não tem problema (alterar o estado)… faz parte do comportamento da entidade… ele é um método da entidade (o que não esta legal é de onde isso é invocado, isso concordo, é discutível). Esta certo que por conveniência ele agregar um requisito a mais do que simplesmente guardar dados pode não parecer bacana, mas o único motivo que achamos isso é por convenção.
Phillip, não estou tirando qualquer razão sua, pelo contrário, o único ponto que não consigo sacar é a questão de regras não poderem ser invocadas pelo repositório, só isso. Apesar de não ser natural ou comum, eu nao erradico essa possibilidade ou vejo quebra de paradigmas… Você esta vendo algo de errado que eu não vejo. Vou reavaliar algumas ações e modelagem, assim como convesar com os desenvolvedores, de qualquer forma, obrigado pela conversa.
Alessandro_Lazarotti
emerleite:
Estou observando a discussão desde o inicio, e tem algo sobre o problema do Alessandro que eu gostaria de comentar:
A facilidade que o Seam trás de acessar os objetos direto, fugindo um pouco do modelo de trabalho anterior do JSF acaba induzindo algumas pessoas a acessar repositório dessa forma direto da JSP. Existem muitas pessoas que estão fazendo isso, porém não acho isso uma boa idéia, justamente por causa desse problema que foi descrito aqui. O cliente precisa de mais uma coisa ai seu repositório vira camada de aplicação, service, ou sei la o que, e ai começa a salada. Mas em fim, tudo isso é a minha opinião.
Depende do requisito Emerson. Como venho dizendo, não defendo que a prática de atribuir responsabilidades a mais para um repository seja algo natural, mas dependendo do contexto ela é válida (ou não, de acordo com a visão do Shoes).
Sobre acessar um repository pela UI, de acordo com o diagrama da Layered Architecture proposto pelo DDD (na primeira página desta thread), não fere qualquer preceito.
Mas amigos, não estou falando pra ninguém sair recheando repositories de códigos… não é essa a idéia…
pcalcado
Ai ai…
Você está colocando palavras na minha boca. Voc6e acabou de descrever insistentemente um exemplo de regras de negócio que eu não considero serem naturais para um repositório. Se você acha seu sistema sobrenatural…
Tudo é questionável mas fazer um acesso da interface (se ainda fosse do controller era uma camada de aplicação mesclada com apresentaçao) direto para o domínio é algo muito estranho a menos que você use naked objects. Se você não acha, ok.
O ponto todo em se adotar uma técnica como Domain-Driven Design é facilitar este tipo de refatoração. Se você precisa mudar boa aprte do seu código para adotar umd esign que você acha razoável então para mim seu código tem problemas (que, como já falei, começam pela aus6encia da camada de aplicação).
O que seu método diz é “quando a entidade X atingir o estado Y eu digo para ela fazer Z”. Toda essa lógica pertence à entidade e quando você tira dela está separando estado e comportamento.
Lezinho:
Phillip, não estou tirando qualquer razão sua, pelo contrário, o único ponto que não consigo sacar é a questão de regras não poderem ser invocadas pelo repositório, só isso. Apesar de não ser natural ou comum, eu nao erradico essa possibilidade ou vejo quebra de paradigmas… Você esta vendo algo de errado que eu não vejo. Vou reavaliar algumas ações e modelagem, assim como convesar com os desenvolvedores, de qualquer forma, obrigado pela conversa.
Desculpa Alessandro mas você está sendo extremamente defensivo e isso tem prejudicado muito qualquer evolução nessa discussão. Se você discorda de mim e quer discutir ótimo, se discorda e não quer discutir ótimo também, o que não dá é para manter esse tom “sobrenatural”.
Alessandro_Lazarotti
pcalcado:
Você está colocando palavras na minha boca.
Minha intenção foi justamente o contrário … como quotei no ultimo post.
… você disse que não achava normal um repositorio ter isso. Se o codigo que postei era sobrenatural então você passa a acreditar na possibilidade de um repositório ter regras ?
Tanto o estado quanto o comportamento estavam na entidade, reveja o código. Se uma façade invocasse o comportamento você acharia errado?
Usei o termo ‘sobrenatural’ como uma brincadeira mesmo para a sua afirmação de que estava dizendo coisas que você não disse, o que ao meu ver, coisa sua também defensiva e sem fundamento (em vista do que você mesmo disse). Do resto, acho que concordo com o fato de que a thread deixou de ‘somar’ (coisa que você tbm não disse, mas dá-se por entender pelo ultimo post).
Emerson_Macedo
Lezinho:
emerleite:
Estou observando a discussão desde o inicio, e tem algo sobre o problema do Alessandro que eu gostaria de comentar:
A facilidade que o Seam trás de acessar os objetos direto, fugindo um pouco do modelo de trabalho anterior do JSF acaba induzindo algumas pessoas a acessar repositório dessa forma direto da JSP. Existem muitas pessoas que estão fazendo isso, porém não acho isso uma boa idéia, justamente por causa desse problema que foi descrito aqui. O cliente precisa de mais uma coisa ai seu repositório vira camada de aplicação, service, ou sei la o que, e ai começa a salada. Mas em fim, tudo isso é a minha opinião.
Depende do requisito Emerson. Como venho dizendo, não defendo que a prática de atribuir responsabilidades a mais para um repository seja algo natural, mas dependendo do contexto ela é válida (ou não, de acordo com a visão do Shoes).
Sobre acessar um repository pela UI, de acordo com o diagrama da Layered Architecture proposto pelo DDD (na primeira página desta thread), não fere qualquer preceito.
Mas amigos, não estou falando pra ninguém sair recheando repositories de códigos… não é essa a idéia…
Pra não prolongar nem criar outras respostas que falem a mesma coisa, vou usar uma que foi dada logo em seguida.
Este diagrama é utilizado no livro para explicar Camadas apenas -que é um dos capítulos introdutórios. Se for seguí-lo ao pé da letra sua interface ode chamar diretamente um DAO ou mesmo classs JDBC/Hibernate, que estão na Camada de Infra-Estrutura.
Repositório para quê?
Emerson_Macedo
Se você usa esse diagrama pra defender a sua idéia dos repositórios, qualquer um poderá usa-lo para defender a idéia de criar uma JSP com código acessando o banco via JDBC, quebrando todas as camadas. Afinal de contas, o desenho mostra claramente uma seta partindo de User Interface direto para Infrastructure. :shock:
Alessandro_Lazarotti
Dependendo da infraestrutura do projeto, a página pode adicionar no meio persistente registros… sem passar por domain layers, repositórios nem nada … isso sem precisar codificar coisa alguma (ver EntityHome do Seam).
Em outras palavras, um dao, implementado pelo framework, acessa da página a infra. O domínio… continua isolado.
pcalcado
Lezinho:
Dependendo da infraestrutura do projeto, a página pode adicionar no meio persistente registros… sem passar por domain layers, repositórios nem nada … isso sem precisar codificar coisa alguma (ver EntityHome do Seam).
Em outras palavras, um dao, implementado pelo framework, acessa da página a infra. O domínio… continua isolado.
Isolado e sem razão de existir.
Partindo do princípio que você quer um Domain Model -do contrário não há nem porque envolver conceitos de Domain-Driven Design na conversa- se você trata seu banco de dados como persistência e faz isso é a mesma coisa em efeitos práticos que deixar todo os atributos das suas classes como públicos: Você quebra completamente o encapsulamento. Num Domain Model o unico meio legítimo de se chegar aos dados é através do modelo, os dados são apenas uma fotografia do modelo. Se você acessa à fotografia sem passar pelo modelo está acessando dados sem passar pelos objetos.
Emerson_Macedo
Lezinho:
Dependendo da infraestrutura do projeto, a página pode adicionar no meio persistente registros… sem passar por domain layers, repositórios nem nada … isso sem precisar codificar coisa alguma (ver EntityHome do Seam).
Em outras palavras, um dao, implementado pelo framework, acessa da página a infra. O domínio… continua isolado.
Desculpe mas isso já saiu da argumentação para defesa a qualquer custo. Não faz o menor sentido o que você está falando. Para que ter todo o trabalho de organizar as coisas se você vai direto na fonte de dados passando por cima de tudo?
Com esses argumentos não faz mais sentido continuar essa discussão, IMO.
pcalcado
Pensei um pouco e acho que entendi o que você está tentando dizer, Alessandro, me corrije se eu estiver errado.
O que você está tentando dizer é que denro de uma arquitetura de Camadas isso é válido, certo?
Se for isso você está correto, é válido sim, mas foge completamente da filosofia de Domain-Driven Design -assunto da discussão- e do Domain Model em si. Layered Architecture é uma premissa para um bom domínio mas não é porque você tem camadas que tem um domínio bem definido -e DDD é sobre domínios bem definidos.
Alessandro_Lazarotti
Não é bem assim.
Um framework pode lhe garantir a abstração necessária para a fotografia. Como no que acabei de exemplificar, na página eu tenho uma expressionLanguage que possui como alvo um DAO implementado pelo framework (não por mim nem por qualquer outra abstração). Nesta discussão você mencionou que o ideal para um repositório era ele não ser obrigado a persistir dados, isso é possível com 2 linhas de xml.
Como se trata de uma EL na página, se precisar alterar/refatorar o alvo para uma façade, não tenho problema algum. Se não precisar, eu não faço nada e uma configuração declarativa faz isso… como configuração por convenção. Para o código, para os desenvolvedores, para o domínio, simplesmente os dados estão lá, disponíveis para o consumo.
Alessandro_Lazarotti
emerleite:
Lezinho:
Dependendo da infraestrutura do projeto, a página pode adicionar no meio persistente registros… sem passar por domain layers, repositórios nem nada … isso sem precisar codificar coisa alguma (ver EntityHome do Seam).
Em outras palavras, um dao, implementado pelo framework, acessa da página a infra. O domínio… continua isolado.
Desculpe mas isso já saiu da argumentação para defesa a qualquer custo. Não faz o menor sentido o que você está falando. Para que ter todo o trabalho de organizar as coisas se você vai direto na fonte de dados passando por cima de tudo?
Com esses argumentos não faz mais sentido continuar essa discussão, IMO.
E persistência de dados é responsabilidade do domínio?
Alessandro_Lazarotti
pcalcado:
Pensei um pouco e acho que entendi o que você está tentando dizer, Alessandro, me corrije se eu estiver errado.
O que você está tentando dizer é que denro de uma arquitetura de Camadas isso é válido, certo?
Se for isso você está correto, é válido sim, mas foge completamente da filosofia de Domain-Driven Design -assunto da discussão- e do Domain Model em si. Layered Architecture é uma premissa para um bom domínio mas não é porque você tem camadas que tem um domínio bem definido -e DDD é sobre domínios bem definidos.
É isso Shoes. Domain é sobre domínio, e não sobre infra. O assunto decorreu sobre uma observaçao sua em relação a existencia ou não de uma camada de aplicação, o que pode ser útil muitas vezes e em outras não tão necessária, contudo isso tem mais haver com camadas do que DDD propriamente disso.
Inclusive, um tópico sobre isso para continuarmos sobre essa linha (menos DDD e mais camada) pode ser interessante para quem ainda não entendeu sobre a observação que fiz.
Emerson_Macedo
Lezinho:
emerleite:
Lezinho:
Dependendo da infraestrutura do projeto, a página pode adicionar no meio persistente registros… sem passar por domain layers, repositórios nem nada … isso sem precisar codificar coisa alguma (ver EntityHome do Seam).
Em outras palavras, um dao, implementado pelo framework, acessa da página a infra. O domínio… continua isolado.
Desculpe mas isso já saiu da argumentação para defesa a qualquer custo. Não faz o menor sentido o que você está falando. Para que ter todo o trabalho de organizar as coisas se você vai direto na fonte de dados passando por cima de tudo?
Com esses argumentos não faz mais sentido continuar essa discussão, IMO.
E persistência de dados é responsabilidade do domínio?
Não é esse o ponto. Como já foi dito diversas vezes nessa thread, os dados persistentes são um acidente, portanto, não deveriam ser acessados da forma que você disse num Design OO bem definido, seguindo os princípios de Domain-Driven-Design.
Agora, como também foi dito, ser válido em Layered Architecture é uma coisa, ser um Domínio bem definido é outra. Eu tinha entendido desde o começo e que o foco dessa discussão eram práticas de Dominios bem definidos. Anyway …
Alessandro_Lazarotti
… anyway CRUD não tem haver com domínio (tanto que aqui ele foi chamado de acidente, não é mesmo).
Se alguém(ferramenta ou framework que for) faz isso (sem escrever nada de código), sem intervir na modelagem, sem intervir nas idéias e conceitos e ainda por cima é produtivo pra caramba… com certeza é bem vindo.
Emerson_Macedo
Correto. Mas só pra lembrar que seu exemplo do Seam direto no repositório, e este acumulando regras de negócio, não teve nada a ver com isso e não se encaixa nesse caso. Foi isso que se questionou
Alessandro_Lazarotti
Seam direto no repositório? Do que você esta falando?
Uma discussão é sobre ter regras ou não no repositorio, outra coisa foi o questionamento sobre a UI acessar a infra (o que exemplifiquei).
Ao meu ver camada de aplicação é opcional e não afeta o domínio. Se a execução do domínio depende de um flow de sub-instruções, isto deveria estar em um Service e não em uma app-layer.
Emerson_Macedo
É só você ler novamente os posts anteriores.
Ambos já foram discutidos. No caso do acesso ditero ao repositório por parte da UI, na opinião da maioria não foi uma alternativa legal, mas se você gostou, vá em frente.
Em nenhum momento questionou-se a escolha entre Service/App Layer/Colocar tudo no controller, em fim. O que se questionou foi a sua UI não ter uma fronteira bem definida com o restante do sistema.
Alessandro_Lazarotti
Falei de Seam no ‘DAO’ mesmo (infra), repositorio não entra na jogada. Uma página acessando via EL um mecanismo de persistencia criado pelo framework… isso é muito útil para CRUD. Toquei no assunto mediante ao questionamento de via UI acessar DAO.
Outra coisa foi o assunto abordado de repositorios (não DAO) serem disponibilizados na UI. Assim como acesso entidades de domínio e Services, não encontrei motivos para não acessar os repositórios (nakeds? pode ser).
A não ser que você utilize SessionFaçade, não vejo pq fazer isso sempre.
Emerson_Macedo
Lezinho:
Falei de Seam no ‘DAO’ mesmo (infra), repositorio não entra na jogada. Uma página acessando via EL um mecanismo de persistencia criado pelo framework… isso é muito útil para CRUD. Toquei no assunto mediante ao questionamento de via UI acessar DAO.
Outra coisa foi o assunto abordado de repositorios (não DAO) serem disponibilizados na UI. Assim como acesso entidades de domínio e Services, não encontrei motivos para não acessar os repositórios (nakeds? pode ser).
Se achou bom pra vc, então toca o barco.
A não ser que você utilize SessionFaçade, não vejo pq fazer isso sempre.
Ninguém disse sempre. O fato é que no seu exemplo, vc teve problemas pois seu repositório passou a ter responsabilidades demais. O fato aqui é que no seu caso, veja bem “seu caso e exemplo que você mesmo escreveu”, a opção adotada trouxe problemas, e IMO tende a acontecer mais vezes. De qualquer forma, seu exemplo também não era um simples CRUD, tanto que seu cliente pediu uma funcionalidade antes da gravação do registro. Portanto, não misturemos as coisas.
Alessandro_Lazarotti
Ao meu ver não pela falta de uma application layer. Mesmo se ela existisse, eu teria que garantir que todo acesso ao repositório.add daquele objeto, deveria ser feito por aquela façade da aplicação. Eu mesmo disse que uma solução para aquele exemplo ela delegar a responsabilidade para um Service (nao App-L.), mas citei tbm o problema que pode causar. Contudo uma refatoração do modelo como o Shoes descreveu fica bom, com isso eu concordei.
Mas isso foi sobre camadas, nem tinha nada haver com o exemplo. Teve mais haver com afirmaçoes como essa:
pcalcado
CRUD faz arte do domínio, CRUD é como são persistidos, obtidos, atualizados e removidos objetos, poucas coisas têm tanta importância. Qulquer lógica de negócio (e CRUD, por mais simples que seja, é lógica de negócio) deve passar pelo domínio.
Alessandro_Lazarotti
Como são persitidos e removidos o objeto? Estas não são aquelas questões de que isso é algo incomum para o objeto em sí (o que foi classificado como acidente)? Para o domínio, não seria interessante apenas que eles existissem … pronto para eventuais buscas?
Embora factories ofereçam capacidade para montar entre outras coisas objetos mais complexos, como Aggregaties, isso pode ser feito (na maioria das vezes) de maneira transparente pelos frameworks de persistências, assim dispensando em algumas vezes um intermédio necessário (no caso de repositórios que possuem sua implementação plugada em um DataMapper). Acredito que o mesmo valha para situações de persistência, atualização ou exclusão, onde alguma convenção no código pode tratar de forma natural estas atividades onde for cabível.
Se algum dia eu mudar a abstração do Repository, de maneira que não se utilize mais DataMapper mas qualquer outro meio persistente, eu crio mecanismos para montar de forma eficiente os objetos para aquela abstração, mas isso apenas se precisar, de forma incremental. O uso para operações de CRUD faço a mesma coisa, se um framework que me ajuda na tarefa de forma transparente (como AR do Rails em sua forma mais simples, ou o Seam em java) não interessar mais ou não servir, crio uma façade que delegue para o domínio a tarefa.
pcalcado
Lezinho:
Como são persitidos e removidos o objeto? Estas não são aquelas questões de que isso é algo incomum para o objeto em sí (o que foi classificado como acidente)? Para o domínio, não seria interessante apenas que eles existissem … pronto para eventuais buscas?
Embora factories ofereçam capacidade para montar entre outras coisas objetos mais complexos, como Aggregaties, isso pode ser feito (na maioria das vezes) de maneira transparente pelos frameworks de persistências, assim dispensando em algumas vezes um intermédio necessário (no caso de repositórios que possuem sua implementação plugada em um DataMapper). Acredito que o mesmo valha para situações de persistência, atualização ou exclusão, onde alguma convenção no código pode tratar de forma natural estas atividades onde for cabível.
A única ocasião onde você precisa persistir seu objeto é quando ele muda de estado e onde ele muda de estado é no domínio. Se seu objeto não muda de estado na interface não há porque ele ser persistido na interface, se muda de estado na interface isso é um SmartUI e não um Domain Model.
Como disse antes, acredito que a ênfase que você deu em “não alterar muitas linhas de código” algumas mensagens atrás pode ser decorrente deste tipo de design. O ponto todo em ter uma Camada de Negócios é abstrair estas mudanças, como elas estão vazando para a interface qualquer mudança (como introduzir o observer mencionado antes) causa um problema para alterar todos os lugares.
Note que você pode considerar seu repositório como bom candidato para ser levado até à Camada de Apresentação e aind assim ter Domain-Driven Design, mas como falei seus problemas em implementar lógica de neócio fora do Repository e em ter que alterar muito código para mudanças simples podem ser decorrentes disso.
O Rails é um péssimo exemplo para este tópico, não há nenhuma preocupação com Domain-Driven Design nele, a lógica de persistência fica dentro das classes de negócio. Se voê quiser algo parecido tudo bem mas você está abrindo ão de Domain Model e consequentemente de Domain-Driven Design.
Alessandro_Lazarotti
Phillip, você exibe formulários para o usuário inputar dados e estes estarem disponíveis para manipulação do sistema, certo? Quase sempre (não necessariamente) estes dados serão os mesmos que irão compor as informações dos objetos de domínio - sendo assim você não realiza binding dos campos do formulário diretamente nos objetos de domínio para que seu estado não seja alterado diretamente pela UI ? (durante o request, seu objeto receberá os dados da UI, seu estado estará alterado ou inicializado). Como você lida com isso?
Evans chama de SmartUI aquelas aplicações feitas no maior estilo “ASP-PHP” do começo deste século, onde na página se abarrotava lógica de negócio:
… ou o estilo VB6/Delphi:
Nas desvantagens do modelo, ele cita dificuldades para integrar a aplicação, falta de reaproveitamento de código entre outros. Mas o que sugeri não foi colocar as regras e lógicas de negócio na UI e estas desvantagens citadas não se aplicam neste caso, a camada de negócio existe. O que a UI tem é a invocação dos serviços da próxima camada, assim como ele disponibiliza os dados dos objetos que estão nesta outra camada adjacente. Da mesma forma que a UI faz entidade.getAtributo() em ${entidade.atributo} nos seus campos de um formulário, ela faz #{entidade.executaComportamento} no botão. o comportamento continua na entidade e pode ser utilizado em outras parte do sistema, (ele não esta na UI como Evans cita no anti-pattern).
Pois é, eu utilizo eles na camada de apresentação. A questão da dificuldade do refactoring Shoes, é mais atrelada a modelagem prévia do que com a interação com o resto do sistema. No seu segundo exemplo com Observer, caso fosse remover do Repository a lógica e adiciona-la a um Service, eu poderia remover a chamada antiga referenciada para o repository da UI e atribui-la agora para o novo Service. Caso tivesse a app-layer, o que mudaria é que o ponto de mudança ficaria na classe por detras da página, e não nela própriamente dita (o que pode ser interessante caso ela for reaproveitável).
Embora eu não citei explícitamente Rails na primeira página desta thread, eu estava pensando nele no começo desta thread, vide a primeira página:
… ainda que saiba que uma coisa é Activerecord e outra é como Rails se vale disso.
O que quis dizer quando citei o rails e o seam nas ultimas mensagens é fazer valer de algumas facilidades em relação as tecnologias sem ferir necessariamente a arquitetura do domínio. A maioria do sistema é repleta de cadastrinhos necessário do tipo “Id” e “Descrição” (entidades fracas na maioria das vezes anêmicas e sem comportamento algum). Se algo produtivo que não me force escrever código intrusivo da tecnologia no domínio e que resolva um problema de forma simples (sem codificar SmartUI), pq não usar? Se algo mudar e o simples “cadastro mágico”, sem código algum, ter um valor agregado maior para a aplicação, então neste momento eu refatoro aquele ponto para aplicar os padrões do domain.
Faça a analogia a uma entrega de funcionalidade em um sprint Scrum… você faz uma carga de dados em scripts para o cliente e ele utiliza uma tela mesmo sem possuir uma outra tela de cadastros (já q vc disponibilizou os dados pra ele), em outro momento (sprint) vc entrega o cadastro. Se um framework disponibiliza os dados de forma satisfatória, trasnparente e eu não preciso naquele momento de qualquer outro recurso extra do domínio para executar algo, então eu deixo para montar o que falta quando precisar e se precisar.
[]´s
pcalcado
Não entendi o problema, meus formulários lidam com objetos do modelo, não com classes da inra-estrutura.
Se você chama a persistência diretamente da interface você tem que ter processamento de regras de negócio em algum lugar, se não é no Domain Model é na interface, logo qual a diferença pra Delphi/VB?
Eu discordo, mas já falei muito sobre isso e, sinceramente, não tenho mais o que acrescentar.
Você está msiturando conceitos completamente diferentes aqui. Uma coisa é o design ideal, que é o que se tenta fazer com Domain-Driven Design, outra coisa é como se chega nele. Se você colocou o repositório ali porque não tem tempo de consertar agora é uma coisa completamente diferente, eu estou falando sobre o design ideal da aplicação.
Emerson_Macedo
pcalcado:
Lezinho:
Evans chama de SmartUI aquelas aplicações feitas no maior estilo “ASP-PHP” do começo deste século, onde na página se abarrotava lógica de negócio:
… ou o estilo VB6/Delphi:
Nas desvantagens do modelo, ele cita dificuldades para integrar a aplicação, falta de reaproveitamento de código entre outros. Mas o que sugeri não foi colocar as regras e lógicas de negócio na UI e estas desvantagens citadas não se aplicam neste caso, a camada de negócio existe. O que a UI tem é a invocação dos serviços da próxima camada, assim como ele disponibiliza os dados dos objetos que estão nesta outra camada adjacente. Da mesma forma que a UI faz entidade.getAtributo() em ${entidade.atributo} nos seus campos de um formulário, ela faz #{entidade.executaComportamento} no botão. o comportamento continua na entidade e pode ser utilizado em outras parte do sistema, (ele não esta na UI como Evans cita no anti-pattern).
Se você chama a persistência diretamente da interface você tem que ter processamento de regras de negócio em algum lugar, se não é no Domain Model é na interface, logo qual a diferença pra Delphi/VB?
Acho que ele está fazendo um sistema tão simples, sem nenhuma regra de negócio, que apenas realiza cadastros e nunca vai ter necessidade de ter um Domain Model de verdade. Portanto, pode fazer em ASP|PHP que vai sair muito mais rápido. Ou até mesmo em .Net usando Visual Studio e o recurso de Table Module que já é nativo da plataforma. Ficará pronto em segundos.
Alessandro_Lazarotti
Shoes, seu formulário lida com objetos de modelo na camada de apresentação, ele recebe e exibe dados por essa camada. Ao receber os dados pelo formulário e este ser submetido, o próprio binding dos campos atualiza o estado de seu objeto em qualquer ferramenta MVC. A camada de negócio já recebe este objeto em novo estado atualizado, é sobre isso que postei.
Processamento de regra de negócio eu tenho e esta na camada de negócio:
A persistencia nas RAds é tratada sobre um componente pouco reutilizável que muitas vezes é colocado escancarado sobre a própria UI. Ja nas páginas não existe componente associado, uma EL que pode ser qualquer coisa que faz as invocações.
Alessandro_Lazarotti
Acho que você não leu as mensagens na íntegra Emerson, ou faz que não leu:
… em nenhum momento disse que o sistema é apenas isso. Se sua aplicação não possue um cadastro que se enquadre nesta regra, parabéns.
Emerson_Macedo
Engraçado é que no seu próprio exemplo tinha um simples cadastrinho que não ia dar em nada. Acontece que seu cliente pediu para realizar a tarefaX antes de gravar os dados e eis que surge uma regra de negócio no repositorio.
Estamos repetindo as mesmas coisas várias vezes de forma diferente. Não está mais valendo apena. Desculpe qualquer coisa e abraços.
Alessandro_Lazarotti
emerleite:
Engraçado é que no seu próprio exemplo tinha um simples cadastrinho que não ia dar em nada. Acontece que seu cliente pediu para realizar a tarefaX antes de gravar os dados e eis que surge uma regra de negócio no repositorio.
Estamos repetindo as mesmas coisas várias vezes de forma diferente. Não está mais valendo apena. Desculpe qualquer coisa e abraços.
… e como já disse várias vezes, eu poderia em vez de colocar a regra no repositório, colocar em um Service (como já postei aqui)… a escolha de colocar no repositório foi minha (era só fazer a chamada ao service no lugar do repository). Outra coisa é o debate sobre utilizar recursos do framework para persistência transparente e isso de nada tem haver com o exemplo citado.
Sim, estamos repetindo.
Abraços
pcalcado
Lezinho:
Shoes, seu formulário lida com objetos de modelo na camada de apresentação, ele recebe e exibe dados por essa camada. Ao receber os dados pelo formulário e este ser submetido, o próprio binding dos campos atualiza o estado de seu objeto em qualquer ferramenta MVC. A camada de negócio já recebe este objeto em novo estado atualizado, é sobre isso que postei.[…]
A persistencia nas RAds é tratada sobre um componente pouco reutilizável que muitas vezes é colocado escancarado sobre a própria UI. Ja nas páginas não existe componente associado, uma EL que pode ser qualquer coisa que faz as invocações.
Eu tenho a impressão que estamos nos repetindo. Possivelmente não concordamos e ponto.
Para clarificar, existem dois problemas sendo lidados nesta thread:
Camada de Apresentação acessando diretamente Repositorio: Apesar de não ferir Camadas isso faz co que elas perdam bastante de seu sentido. Sua UI deveria conhecer sobre a lista de itens retornada pelo repositorio, nao pelo repositorio em si. Existem diversos problemas decorrentes disso e para mim você já está vivendo um deles quando tem que colocar regras de negócio no repositório simplesmente para que elas façam parte do fluo, já que você não tem um orquestrador de fluxo que seria a Camada de Aplicação.
Camadas: Para justificar o problema acima você colou um diagrama onde superiores acessam as ultimas Camadas. Eu afirmei que isso nao é um problema mas que no ontexto de DDD é usado no livro apenas como introdução à Camadas, e que se isso fosse para ser seguido à risca você teria interface -> DAO (ou mesmo interface -> JDBC) como algo completamente aceitável. Você falou que dpeendendo da infra-estrutura isso era OK. O que eu fiquei repetindo nos posts subsequentes é que isso Não é aceitável para um Domain Model sadio -pensando em melhor design possível, não em design incremental, YAGNI ou pragmatismo.